What Is Serverless Computing A Practical Explainer
What Is Serverless Computing? A Practical Explainer for IT Professionals
Let's address a common point of confusion right from the start: the term "serverless" is a little deceptive. While your application code runs without you needing to provision or manage servers, it doesn't mean servers have magically disappeared. Quite the contrary! Behind the scenes, powerful cloud infrastructure, managed by providers like AWS, Azure, and Google Cloud, is working tirelessly. The game-changing difference for IT professionals and developers is that you are completely abstracted from these underlying machines.
Imagine you're an ambitious restaurateur. In a traditional model, you'd lease a building, install a full kitchen with ovens, refrigeration, and prep stations, hire staff, and manage everything from gas lines to health inspections. That's akin to managing your own servers. In a serverless model, you simply create a menu (your application logic), and when a customer orders, a sophisticated catering service (the cloud provider) instantly prepares and delivers the dish. You only pay for the ingredients and the cooking time, not for the idle kitchen space or utility bills.
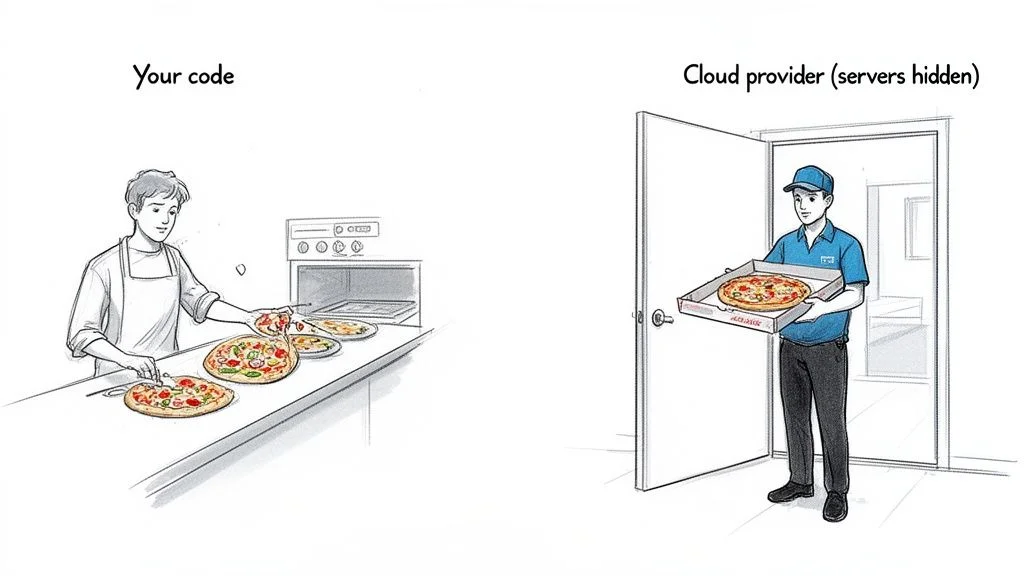
In the serverless world, you supply the "menu"—your application code—and a cloud provider like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud takes care of the entire kitchen. They handle the infrastructure, scaling, patching, and maintenance, allowing your team to focus exclusively on building innovative features.
This approach fundamentally shifts the focus of development. Instead of your teams grappling with server provisioning, operating system patching, and capacity planning, they can channel all their energy into what truly drives business value: developing features that your customers will love and delivering them faster.
The Shift in Responsibility: Why It Matters for Certifications
At its core, serverless computing is about significant infrastructure abstraction. Your application isn't a monolithic program residing on an always-on server. Instead, it's decomposed into small, independent functions that are invoked only when needed. Understanding this shift is crucial for anyone pursuing cloud certifications like AWS Certified Cloud Practitioner, Azure Fundamentals, or Google Cloud Digital Leader, as it underpins modern cloud architecture design.
These functions are brought to life by events. An event can be virtually anything: an API call from a mobile app, a new image uploaded to a storage bucket, a change in a database, a message in a queue, or even a scheduled timer. When a trigger fires, the cloud provider instantly allocates the necessary computing resources, runs your code, and then deallocates those resources. A key benefit is the pay-per-use model, where you're billed only for the exact compute time consumed, often measured in milliseconds. This cost efficiency is a major topic in cloud optimization exam objectives.
The central tenet of serverless is straightforward: You supply the application code, and the cloud provider manages everything else. This event-driven, pay-per-use model eliminates the burden of managing persistent servers, empowering developers to concentrate solely on application logic and feature development. It's a paradigm shift towards greater operational efficiency and agility, often discussed in ITIL and DevOps contexts.
This model is rapidly gaining traction. The serverless computing market was estimated at USD 24.51 billion in 2024 and is projected to reach USD 52.13 billion by 2030. These figures, which you can explore further in this comprehensive serverless computing industry analysis, highlight the increasing importance of serverless skills for IT professionals looking to advance their careers.
Serverless Vs Traditional Servers At A Glance
To solidify your understanding, a direct comparison between serverless and traditional server management is invaluable. The table below outlines the distribution of responsibilities in each model, illustrating the profound operational shift serverless introduces.
| Aspect | Traditional Server Management | Serverless Computing |
|---|---|---|
| Server Provisioning | Manual setup or complex scripting | Fully automated by the cloud provider |
| Scaling | Manual configuration or intricate auto-scaling rules | Automatic and seamless scaling based on real-time demand |
| Cost Model | Billed for allocated resources (even when idle) | Pay-per-use (billed only for execution time) |
| Maintenance | Operating system patching, security updates, capacity planning | All underlying infrastructure maintenance handled by the provider |
| Developer Focus | Managing servers & writing application code | Exclusive focus on writing application code |
As evident from the table, the contrast is significant. The serverless approach is engineered to offload nearly all operational overhead, enabling your team to innovate more rapidly and efficiently. This aligns with core principles of operational excellence and cost optimization, key areas evaluated in many cloud certification exams.
Exploring FaaS and BaaS: The Core Components of Serverless
We've established that serverless abstracts away server management. But how exactly is this achieved in practice? The answer lies in two foundational models that underpin virtually every serverless architecture: Function as a Service (FaaS) and Backend as a Service (BaaS). For certification candidates, understanding their distinct roles and how they integrate is critical.
Think of them as two distinct yet highly complementary toolsets. FaaS is where your custom code lives and executes, while BaaS provides a suite of essential, pre-built services that most modern applications require, abstracting away their underlying infrastructure.
Function as a Service (FaaS): The Compute Engine
Function as a Service, or FaaS, represents the true compute power of serverless computing. It's the environment where your event-driven code is executed. If building an application is like ordering a custom pizza, FaaS is the incredibly efficient, on-demand kitchen that instantly appears, prepares your specific toppings (your code), and bakes it perfectly—but only when an order is placed.
You package your application logic into small, self-contained units called functions. Each function is designed to perform a single, specific task, such as processing a payment, resizing an image for a web gallery, or sending a confirmation email. These functions remain dormant, incurring no cost, until an event triggers their execution.
When a trigger occurs—for instance, a user uploading a file, an API call, or a database change—the cloud provider's platform instantly provisions a temporary execution environment, runs your function, and captures the result. As soon as the task is complete, the environment is deallocated. This entire process can occur within milliseconds.
This event-driven, "just-in-time" execution is what makes FaaS exceptionally powerful. You are not paying for servers to sit idle 24/7. Instead, you only pay for the precise compute time your code consumes, often down to the millisecond. For applications characterized by unpredictable or spiky traffic, the resulting cost savings can be substantial, a core benefit often highlighted in cloud economics modules for certifications.
The most widely recognized FaaS offering is AWS Lambda. For those preparing for AWS certifications, it's invaluable to delve deeper into how AWS Lambda works and its common use cases, as it's a frequent topic in exams. Other prominent FaaS services include Azure Functions and Google Cloud Functions.
Backend as a Service (BaaS): The Pre-Built Utilities
While FaaS is responsible for executing your custom code, Backend as a Service (BaaS) furnishes all the ready-made backend components that modern applications typically rely on. It's about consuming services rather than building or maintaining them.
Consider constructing a new building. Instead of attempting to build your own power plant, water treatment facility, and sewage system from scratch, you simply connect to the existing city utility grid. BaaS serves as that utility grid for your application. It provides a suite of professionally managed services that you can integrate into your application via simple API calls, alleviating the burden of self-managing these complex components.
Common BaaS offerings crucial for modern application development include:
- Authentication: Fully managed services for user sign-up, sign-in, and robust security (e.g., AWS Cognito, Auth0). This removes the security and scalability burden of managing user identities.
- Databases: Highly scalable NoSQL or SQL databases that your application can interact with directly, without you ever needing to worry about the underlying servers (e.g., Google Firebase, Amazon DynamoDB). These are essential for persistent data storage in serverless applications.
- File Storage: Object storage solutions for user-generated content such as photos, videos, or documents (e.g., Amazon S3, Google Cloud Storage). This offers virtually limitless scalability and high durability.
- Push Notifications: Services for reliably sending alerts and updates to users across their mobile or web applications.
FaaS and BaaS: A Synergistic Approach
The true power and efficiency of a serverless architecture become apparent when you combine FaaS and BaaS. Developers leverage BaaS services as robust, managed foundational building blocks and then write FaaS functions to act as the "glue," implementing the custom business logic that orchestrates these services and brings the application to life. This integrated approach is a cornerstone of modern cloud-native development, a frequently examined topic in advanced cloud certifications.
Let's illustrate with a classic example: a photo-sharing application.
- A user uploads a new photo from their mobile device. This action directly writes the image data to a cloud object storage bucket, which is a BaaS service (e.g., Amazon S3).
- That file upload event automatically triggers a predefined FaaS function (e.g., an AWS Lambda function).
- The FaaS function executes its code: it might create a smaller thumbnail of the photo, perhaps add a watermark, and then write the photo’s metadata (e.g., user ID, timestamp, S3 object URL) into a BaaS database (e.g., Amazon DynamoDB).
In this entire workflow, the only custom code the developer needed to write was for the FaaS function itself. User authentication, the scalable file storage, and the high-performance database were all ready-to-use BaaS components. No servers were ever provisioned, no operating systems patched, and no manual scaling was required. That’s the profound essence of building a truly serverless application.
Reflection Prompt: Consider how this serverless architecture simplifies deployment and maintenance compared to a traditional three-tier application. What benefits would a project manager (PMP certified) see in terms of resource allocation and time-to-market?
How Serverless Architecture Actually Works
To fully grasp serverless, you must adopt an event-driven mindset. The entire model is predicated on an event-driven architecture, meaning it's inherently designed to await a specific occurrence and then react to it instantaneously. This reactive pattern is fundamental to understanding serverless operations, a key concept for any cloud architect or developer.
Think of it like a motion-activated security light. Most of the time, it remains completely off, consuming zero power. It's simply waiting. But the moment it detects motion—an event—it immediately activates, performs its designated task (the function), and then deactivates.
Serverless computing operates on this precise logic. Your code resides as individual, dormant functions. When a specific trigger occurs, the cloud provider instantly spins up a temporary, isolated execution environment, runs your function to process the event, and then efficiently tears down that environment. You only incur costs for those brief moments the "light" was on.
This approach is incredibly powerful because it perfectly aligns your operational costs with actual usage. You are no longer paying for expensive servers to sit idle, waiting for requests that may or may not materialize. This direct correlation between usage and cost is a significant advantage for financial planning in IT projects.
The Lifecycle of a Serverless Function
So, let's trace what happens under the hood when an event—such as a user accessing an API endpoint or uploading a file to storage—initiates a serverless function. The cloud provider autonomously manages this rapid-fire sequence, making it transparent to the developer.
- Event Trigger: The process begins when a pre-configured event source sends a signal. This can range from an incoming HTTP request via an API Gateway to a new message arriving in a queue service (e.g., SQS, Azure Service Bus) or even a simple scheduled timer (e.g., cron-like events).
- Container Allocation (Cold Start): If a function hasn't been invoked recently, the platform identifies an available server and provisions a tiny, short-lived container or execution environment. This environment contains everything necessary to run your code, including the language runtime (e.g., Python, Node.js, Java) and your specific function code. This initial setup introduces a slight delay known as a "cold start."
- Code Execution: Your function's code runs within this secure, isolated environment, processing the data provided by the event trigger to perform its designated work.
- Resource Deallocation/Shutdown: As soon as the function successfully completes its task, the container is destroyed or recycled. The computing resources are immediately freed up, ready to be allocated for another invocation elsewhere.
This diagram helps visualize how the core pillars of serverless—FaaS and BaaS—work together to make this happen, forming a cohesive and scalable architecture.
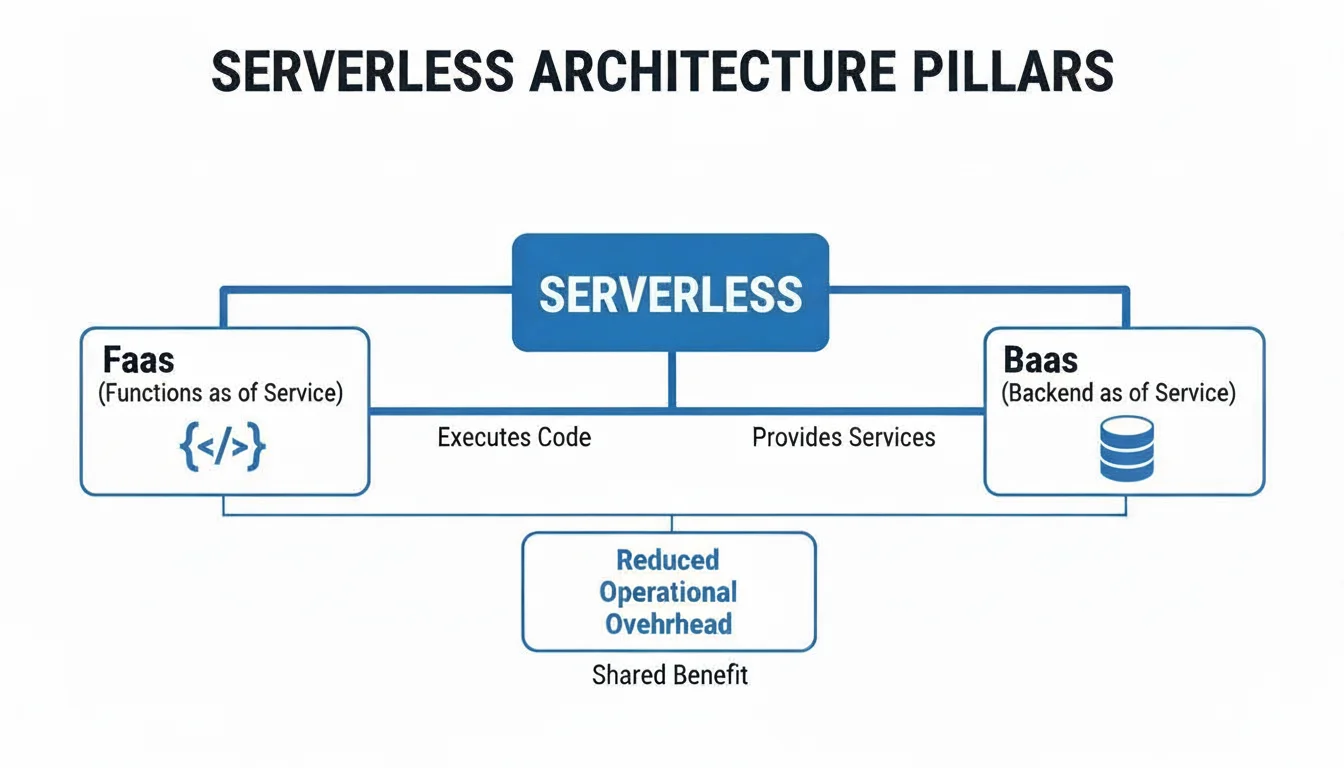
As illustrated, Functions as a Service (FaaS) acts as the dynamic engine that executes your event-driven code. Concurrently, Backend as a Service (BaaS) provides all the managed, persistent services—like databases and storage—that your functions need to interact with, ensuring data persistence and availability.
Understanding Cold Starts: A Certification Consideration
This on-demand execution model introduces a unique operational characteristic known as a cold start. If your function hasn't been invoked for a certain period, there won't be an active container readily waiting. When a new request arrives, the cloud provider must perform the initial setup steps: finding a server, creating a fresh container, and loading your code. This initial provisioning process adds a small amount of latency to the function's execution. That delay is precisely what we refer to as a cold start.
Once a function has executed, the provider often keeps that container "warm" for a brief duration, anticipating potential follow-up requests. If another request arrives quickly within this warm period, the function can execute almost instantaneously without the startup delay, resulting in a warm start.
A cold start is the initial latency experienced when a serverless function is invoked for the first time after a period of inactivity. While this delay is typically just a few hundred milliseconds, it can be a critical factor for highly performance-sensitive applications, such as real-time user interfaces. Fortunately, cloud providers offer mitigation strategies like provisioned concurrency, which keeps a specified number of function instances warm and ready, minimizing latency for critical workloads. Understanding cold starts and their mitigation is a common topic in cloud architecture and optimization exams.
The Stateless Nature of Serverless: A Design Principle
One of the fundamental principles of serverless design is that functions must be stateless. This dictates that you must treat every single invocation as an entirely new, independent event. You can never assume that data or memory from a previous run will persist or be available for the next one. This architectural constraint is crucial for achieving the massive scalability and fault tolerance inherent in serverless platforms.
Why is this principle so vital? Because there is no guarantee that your function will execute on the same physical server or even in the same container twice. Attempting to store application state—such as a user's session ID, shopping cart contents, or temporary file data—inside the function's temporary execution environment is a surefire way to lose data, as it will all vanish the moment the execution concludes and the container is deallocated.
So, where does all this critical state reside? This is precisely where Backend as a Service (BaaS) becomes an indispensable partner. Instead of storing state within your transient function, you offload it to an external, professionally managed service designed for persistence and scalability.
- User Sessions: Leverage managed database services like Amazon DynamoDB or specialized caching services like AWS ElastiCache (Redis/Memcached).
- File Data: Store user-generated files, documents, and media in highly durable object storage services like Amazon S3 or Google Cloud Storage.
- Application State & Workflows: Manage complex, multi-step application workflows and their state using dedicated state machine services like AWS Step Functions, which orchestrate multiple FaaS functions.
This design enforces a clean separation between your application's ephemeral logic (FaaS) and its persistent data (BaaS), which is a core tenet of building resilient, scalable, and cloud-native applications. For those pursuing certifications, understanding this separation of concerns is fundamental for designing robust distributed systems. To see how these pieces integrate into modern development, it can be helpful to examine a few popular tech stack examples that incorporate serverless components.
Evaluating The Benefits And Tradeoffs Of Going Serverless
Adopting a serverless architecture represents a significant departure from traditional application deployment. It offers compelling advantages, but it's not a universal solution. Like any major technology decision, a thorough evaluation of its pros and cons is essential to determine if it aligns with your project's specific requirements and organizational goals. For cloud solution architects, this cost-benefit analysis is a critical skill.
This market trajectory underscores its impact, with projections showing the serverless market growing from approximately USD 32.59 billion in 2026 to an impressive USD 91.56 billion by 2031. This isn't merely a niche trend; it signifies a substantial and ongoing shift in cloud computing strategies. Detailed market projections can be explored on Mordor Intelligence for deeper insights.
The Upside: Why Teams Are Embracing Serverless
The most compelling advantage of serverless is its ability to liberate development teams from infrastructure management, allowing them to focus almost exclusively on code. This core benefit translates into several powerful advantages that businesses and their IT teams often experience rapidly.
Firstly, consider the impact on your cloud expenditure. Serverless operates on a strict pay-per-use cost model, meaning you are billed only for the exact duration your code is executing—typically measured in milliseconds. The significant costs traditionally associated with idle servers awaiting traffic are virtually eliminated. This model is a game-changer for applications with unpredictable, fluctuating, or spiky traffic patterns.
Secondly, the magic of automatic scaling is a major draw. When your application experiences a sudden surge in user requests, the cloud platform seamlessly handles the increased load. You're spared the operational scramble of manually provisioning more servers, configuring load balancers, or optimizing cluster resources. Whether your application receives ten requests or ten million, the underlying infrastructure scales up and down effortlessly, ensuring consistent responsiveness and availability. This elastic scalability is a cornerstone of modern cloud design and a frequent topic in certification exams.
For many development and operations teams, the ultimate win is accelerated developer productivity. By abstracting away server management—eliminating tasks like OS patching, capacity planning, and security hardening—your developers are empowered to dedicate their expertise to what they do best: writing high-quality code that solves business problems and shipping new features at a much faster pace. This agility translates directly into faster time-to-market and increased business competitiveness.
The Other Side Of The Coin: Potential Downsides
While the advantages of serverless are compelling, adopting it without a clear understanding of its inherent tradeoffs can lead to unexpected challenges. These often necessitate a different architectural mindset and operational approach.
A significant consideration is vendor lock-in. When you build your application using a specific cloud provider's proprietary serverless services, such as AWS Lambda, Amazon API Gateway, and Amazon DynamoDB, these services are designed to integrate seamlessly within that ecosystem. The consequence is that migrating your entire serverless application to a different cloud provider can become a complex, time-consuming, and expensive undertaking due to the proprietary nature of these services and their APIs.
Debugging and troubleshooting also become inherently more complex in a serverless environment. Instead of a single, monolithic application, you're now dealing with a distributed system composed of potentially dozens or even hundreds of small, independent functions. Tracing a single user request across this distributed landscape to pinpoint an error can feel like searching for a needle in a haystack. Robust observability and monitoring tools—including centralized logging, metrics, and distributed tracing—are not merely desirable features; they are absolutely essential for effective operations.
Finally, you must contend with cold starts. As previously discussed, the initial delay when a function executes for the first time after a period of inactivity can impact user experience. For applications demanding lightning-fast, highly predictable response times (e.g., real-time gaming, financial trading platforms), this inherent latency might be a critical limiting factor.
Reflection Prompt: How might the concept of vendor lock-in influence strategic decisions for a company with a multi-cloud strategy? What architectural patterns could help mitigate this risk?
Serverless Computing: Benefits Vs. Tradeoffs
To provide a balanced perspective, this table summarizes the key advantages and potential disadvantages that IT professionals should carefully consider when evaluating serverless adoption. Comparing serverless functions (e.g., Lambda) to virtual machines (e.g., EC2) is a common analysis for solution architects, and resources like EC2 vs Lambda offer practical insights into these differences.
| Benefits (Pros) | Tradeoffs (Cons) |
|---|---|
| Pay-per-use cost model drastically reduces expenses for idle time. | Vendor lock-in can make migrating to alternative cloud providers challenging. |
| Automatic, seamless scaling effortlessly handles unpredictable traffic spikes. | Increased operational complexity in debugging and monitoring distributed systems. |
| Accelerated developer velocity by allowing focus solely on writing application code. | Potential performance latency due to cold starts for specific use cases. |
| Reduced operational overhead with no server provisioning or maintenance required. | Resource limitations on function execution time, memory, and concurrent invocations. |
| Enhanced fault tolerance as functions are isolated and automatically replaced upon failure. | Different security model requiring granular IAM permissions for each function. |
Ultimately, deciding whether to embrace serverless means carefully weighing these factors and determining which align most closely with your project's unique requirements. The optimal choice always depends on the specific needs of your application, the capabilities of your team, and your overarching business objectives.
Practical Use Cases For Serverless Technology
Understanding the theoretical underpinnings of serverless is one thing; seeing its real-world applications is where the concept truly comes alive. While serverless isn't a panacea for every problem, it proves to be a transformative solution in specific contexts. Its core strength lies in enabling developers to disengage from infrastructure concerns and dedicate themselves entirely to writing code that intelligently responds to events.
Let's explore practical scenarios where adopting a serverless approach offers distinct advantages for IT professionals and businesses.
Building Scalable APIs And Backends
This is arguably the most common and compelling use case for serverless, and for excellent reasons. Consider the backend of a typical web or mobile application—for instance, an e-commerce platform that experiences massive traffic surges during holiday sales. In a traditional server environment, you'd be compelled to provision enough capacity to handle that peak load, meaning your expensive hardware or virtual machines sit idle for the vast majority of the time, incurring unnecessary costs.
Serverless completely inverts this model. Each incoming API request simply triggers a dedicated function. It is irrelevant whether your application receives ten requests or ten million; the cloud provider automatically manages the underlying scaling. This makes serverless an ideal fit for constructing microservices architectures, where each function can represent a small, independent service responsible for a single business capability, such as processPayment, updateUserProfile, or getProductDetails.
For example, you could implement an AWS Lambda function exposed via an Amazon API Gateway endpoint. When a customer completes a purchase through your frontend application, it sends a request to this endpoint. The Lambda function is instantly invoked, processes the order details, updates your inventory database (a BaaS service), and might even trigger another function to send a confirmation email. This entire workflow is incredibly efficient, scales effortlessly, and costs nothing until a customer initiates a purchase. This pattern is a fundamental building block in cloud architecture certifications.
Processing Real-Time Data Streams
In today's interconnected world, we are surrounded by devices and systems that generate continuous streams of data—from IoT sensors in industrial environments to user activity logs on websites. Serverless is uniquely suited for ingesting and processing this kind of ephemeral, high-volume data in real-time.
You can configure functions to react instantaneously as new data arrives in a stream. This capability allows you to build incredibly powerful data pipelines for real-time analytics, anomaly detection, fraud prevention, or simply transforming data as it's ingested. This eliminates the need for batch processing, providing insights the moment events occur.
The true power of serverless in data streaming lies in its inherent ability to handle "bursty" and unpredictable workloads. An IoT sensor might transmit data every few seconds and then remain quiet for an hour. A serverless function efficiently processes each event as it arrives, eliminating the need for a dedicated server to sit idle, waiting for the next ping.
A practical example is a logistics company using GPS trackers on its delivery trucks. Every time a truck's location is reported to a data stream like Amazon Kinesis or Azure Event Hubs, an Azure Function or Google Cloud Function can be triggered. This function could log the new coordinates to a database, instantly check if the truck has deviated from its planned route, and potentially send an alert to the dispatch team. This is a classic example of event-driven automation in supply chain management.
Powering Intelligent Chatbots And Voice Assistants
Applications like chatbots and voice assistants (e.g., Amazon Alexa, Google Assistant) demand instantaneous responses to deliver a seamless user experience. Their interaction model—a user poses a question (the event), and a function executes to process the request and generate an answer—is a perfect match for serverless computing.
Given that chatbot traffic can be highly unpredictable, with periods of intense activity followed by lulls, the auto-scaling and pay-per-use model of serverless is invaluable. You avoid the waste of time and resources spent trying to accurately forecast peak traffic demands. Instead, developers can focus entirely on crafting intelligent conversational logic and integrating with other APIs and backend services.
Imagine a banking chatbot built with AWS Lambda. A customer asks, "What's my account balance?" The chatbot platform triggers a Lambda function. In a fraction of a second, that function securely authenticates the user, queries the bank's managed database, and returns the balance. It’s fast, secure, scales automatically to handle thousands of concurrent queries, and costs nothing until a user actually initiates an interaction.
Automating IT And Security Operations (Serverless Ops)
Serverless technology isn't solely for building customer-facing products; it also serves as a potent tool for automating internal IT and security tasks. Those repetitive, manual operational jobs that consume valuable staff time can often be elegantly replaced with simple, event-driven functions. This practice, often referred to as "Serverless Ops," significantly enhances operational efficiency and consistency.
You can create functions that react to specific events occurring within your own cloud account, enabling proactive management and remediation.
- Automated Backups: A function can be scheduled to run every night (e.g., using AWS CloudWatch Events or Azure Scheduler) to create snapshots of your critical databases or file systems, ensuring data resilience.
- Security Remediation: A security alert from a monitoring service (e.g., AWS Security Hub, Azure Security Center) could trigger a function that immediately revokes a compromised API key, isolates an infected virtual machine, or adjusts firewall rules, thereby minimizing potential damage. This demonstrates proactive incident response, a key area for security certifications.
- Cost Management: You could deploy a function that periodically scans for idle or underutilized resources—like old server volumes or unattached IP addresses—and automatically deletes them to optimize your cloud bill. This aligns with cost optimization best practices taught in cloud practitioner certifications.
This transforms your infrastructure into a more self-managing and self-healing system. For example, you could configure a Google Cloud Function to trigger every time a new file is uploaded to a Cloud Storage bucket. The function could automatically scan that file for malware before it's made available to the rest of your application, creating a seamless, automated security checkpoint that enhances your overall security posture.
Ready to take your first steps with serverless? It's an exhilarating way to build applications, promising faster development cycles and greater operational efficiency. However, before you write your first function, a bit of strategic upfront planning can make the difference between a smooth launch and a frustrating experience. For IT professionals pursuing certifications, these foundational best practices are invaluable.
Consider this section as practical advice honed from experience. Taking a moment to address cost management, security implications, and robust monitoring strategies will help you avoid common pitfalls and position your serverless projects for enduring success.
Manage Your Costs Proactively
The pay-per-use model is undoubtedly one of serverless computing's most attractive features, but it is a double-edged sword. While you eliminate the costs associated with idle servers, your expenses are now directly correlated with every single execution. This is fantastic for quiet periods but carries a financial risk if an application experiences unexpected, viral traffic or if a function inadvertently enters an infinite loop.
The last thing any IT manager wants is a surprise cloud bill. To mitigate this, your very first action should be to establish billing alerts and budget notifications within your chosen cloud provider’s dashboard (e.g., AWS Budgets, Azure Cost Management). These serve as crucial safety nets, sending you timely warnings if your spending approaches or exceeds predefined thresholds, allowing you to investigate and intervene before costs become unmanageable. Always begin experimenting within the free tier offered by cloud providers to gain hands-on experience without financial risk. Understanding cost management is a fundamental domain in virtually all cloud certification exams.
Prioritize Security From The Start
With serverless architectures, your security paradigm shifts significantly. You are no longer solely guarding the perimeter of a monolithic application; instead, you are securing potentially hundreds of individual, highly distributed components. Each function represents its own potential entry point, making a "least privilege" mindset absolutely non-negotiable.
The golden rule of serverless security is simple yet profound: grant each function only the exact permissions it requires to perform its specific task, and absolutely nothing more. This principle drastically limits the "blast radius" should any single function ever be compromised, preventing an attacker from gaining broader access.
For instance, if a function's sole purpose is to read a file from an Amazon S3 bucket, its associated Identity and Access Management (IAM) permissions should explicitly allow only read access to that specific bucket and no other resources. It should have zero permissions to delete files, modify databases, or interact with other unrelated services. Correctly configuring these Identity and Access Management (IAM) roles and policies is arguably the most critical security measure you can implement in a serverless environment and is a heavily tested topic in AWS, Azure, and Google Cloud security certifications. For anyone preparing for an AWS exam, our AWS Certified Cloud Practitioner Study Guide delves deep into IAM and other foundational security services, providing essential knowledge.
Implement Robust Monitoring and Observability
When your application is composed of a collection of distributed, ephemeral functions, identifying the root cause of an error can feel like finding a needle in a vast haystack. Traditional log file analysis on its own is often insufficient. You need observability—the capacity to ask detailed, open-ended questions about the internal state of your system to understand what's happening, even when you don't explicitly know what to look for beforehand.
Establish centralized logging and distributed tracing mechanisms from day one. Tools like AWS CloudWatch (with Lambda Insights and X-Ray) or Azure Monitor (with Application Insights) consolidate all your logs, metrics, and traces into a single, navigable platform. This allows you to follow a single user request as it traverses multiple functions, services, and execution environments, making it significantly easier to diagnose bottlenecks, trace errors, and squash bugs. Continuously monitor key metrics such as execution duration, error rates, invocation counts, and cold start times to ensure your application remains performant and your users satisfied. This holistic approach to monitoring is a key aspect of operational excellence in cloud certifications.
Frequently Asked Questions About Serverless
As IT professionals begin to explore serverless computing, certain questions inevitably arise. Let's tackle these common inquiries head-on, as they often get to the core of what distinguishes this model from traditional approaches.
Why Is It Called Serverless If Servers Are Still Used?
This is, without a doubt, the most common question, and for good reason—the name is a bit of a misnomer. Of course, there are still physical servers involved! The crucial distinction is that you, the developer or IT operator, are completely relieved of the responsibility for managing, provisioning, or scaling those servers.
Think of it like the municipal water supply in your home. You don't manage a reservoir, water treatment plant, or complex network of pipes; you simply turn a faucet, and water flows. Serverless applies the same conceptual abstraction to your application code. The cloud provider handles all the intricate work of provisioning, scaling, patching, and maintaining the underlying server infrastructure, freeing you up to concentrate purely on your application logic and business value.
Is Serverless The Same As Containers?
No, serverless and containers are distinct technologies serving different purposes, though they can often complement each other. Containers, managed with tools like Docker and orchestrated by platforms like Kubernetes, are excellent for packaging your application code and all its dependencies into a consistent, portable unit that can run reliably across various environments. The key difference is that with containers, you typically remain responsible for managing the underlying server clusters (e.g., EC2 instances, Azure Virtual Machines) where those containers run, as well as the orchestration and scaling of the containers themselves.
Serverless takes the abstraction a significant step further. It completely abstracts away both the underlying container and the server. You simply upload your function code, define its triggers, and the platform handles everything else—from provisioning the execution environment to scaling up and down, even scaling to zero when the function is not in use. Containers provide excellent application portability; serverless provides ultimate freedom from infrastructure management concerns. Understanding this distinction is vital for cloud architecture and developer certifications, as it helps in choosing the right compute model for specific workloads.
Is Serverless Always Cheaper Than Virtual Machines?
Not always. The economic viability of serverless versus virtual machines (VMs) depends entirely on your specific workload characteristics. For applications with unpredictable, sporadic traffic or long periods of inactivity, the serverless pay-per-use model is a tremendous cost-saver. You pay absolutely nothing when your code is not executing, making it incredibly efficient for bursty workloads.
However, if you have a workload that runs constantly at a high, consistent, and predictable volume—essentially a 24/7 always-on application—a dedicated virtual machine or a containerized solution with a fixed monthly cost might prove to be more economical in the long run. It's a trade-off between the flexibility and cost-efficiency of on-demand execution versus the predictable, often lower, per-hour cost of always-on dedicated resources. Performing a detailed cost analysis based on expected usage patterns is a critical skill for solution architects and is frequently assessed in cloud cost optimization scenarios within certification exams.
Ready to master these cutting-edge cloud concepts and prove your expertise to the industry? MindMesh Academy specializes in providing the focused study materials, practical insights, and evidence-based learning tools you need to approach your certification exams with confidence and achieve success. Start your journey towards becoming a certified cloud professional today by exploring our comprehensive resources at https://mindmeshacademy.com.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 15 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.