What is incident response plan: A Guide to Rapid Recovery
What is an Incident Response Plan (IRP)? A Guide to Rapid Recovery for IT Professionals
An incident response plan (IRP) is an indispensable operational blueprint, guiding your organization's actions the moment a security breach or cyberattack occurs. For IT professionals, understanding an IRP is akin to mastering the emergency protocols for critical systems—it’s about having a predefined, strategic approach rather than reacting in a crisis. Think of it as a digital fire drill that ensures your team can act decisively and effectively, minimizing the fallout from the moment a threat is detected until normal operations are fully restored.
Deconstructing the Incident Response Plan for IT Professionals
At its core, an incident response plan answers one crucial question: "What do we do when something bad happens?" For IT teams, "something bad" could range from a sophisticated ransomware attack encrypting mission-critical servers to an insider threat exfiltrating sensitive customer data.
Without a clear, actionable plan, chaos inevitably ensues. Imagine your network administrators scrambling to identify compromised systems, your security analysts unsure whom to notify, and your legal team unaware of compliance requirements. This disarray leads to wasted time, increased data loss, higher recovery costs, and significant damage to your organization's reputation.
An IRP replaces this potential chaos with a structured, coordinated effort. It meticulously defines roles, responsibilities, communication protocols, and the precise procedures to follow during a security event. This preparation ensures that everyone, from the frontline security operations center (SOC) analyst to the senior management and public relations team, understands their specific function when the pressure is on.
The True Purpose of Planning: Beyond Technical Fixes
The objective of an IRP extends far beyond merely fixing a technical glitch. It's a strategic asset designed to protect the entire business ecosystem, a concept frequently tested in certifications like PMP (project management for recovery efforts) or ITIL 4 (incident management practice). For instance, a focused data breach response plan is specifically engineered to safeguard sensitive customer and company information when it’s most vulnerable.
Here’s what a robust IRP helps your organization accomplish:
- Minimize Damage and Downtime: The primary goal is swift containment of the threat. This involves isolating infected systems, preventing further lateral movement, and reducing operational downtime and financial losses. For example, in an AWS environment, this might mean immediately quarantining compromised EC2 instances or restricting S3 bucket access.
- Protect Reputation and Trust: How an organization responds to a crisis profoundly impacts its public image. A fast, transparent, and competent response can preserve customer trust, mitigate negative press, and soften the long-term blow to your brand's standing.
- Ensure Regulatory Compliance: Numerous industry regulations and data privacy laws (e.g., GDPR, HIPAA, PCI DSS) legally mandate organizations to possess a formal IRP and follow strict breach notification procedures. Failing to comply can lead to severe penalties, including hefty fines and legal ramifications, in addition to the direct costs of the breach.
While an IRP shares goals with other IT processes, its focus is uniquely immediate and reactive to a security event. To grasp how it integrates into the broader operational framework, explore our guide on problem management vs. incident management, which clarifies the distinct yet complementary roles of these critical functions within IT service management.
An IRP is more than a technical document; it is a business resilience tool. Its effectiveness is measured not by its length, but by the speed and clarity it provides when your organization is under attack.
Ultimately, comprehending what an incident response plan is means recognizing it as a strategic guide for organizational survival and recovery in the face of cyber adversity.
The table below outlines the core objectives every IRP is meticulously designed to achieve, providing a clear framework for IT professionals.
Core Objectives of an Incident Response Plan
| Objective | Description | Example Action for an IT Pro |
|---|---|---|
| Minimize Damage & Downtime | Quickly contain the security threat to prevent its spread and impact on critical business operations. | Isolating an infected network segment via firewall rules or quarantining compromised virtual machines in Azure/AWS. |
| Protect Reputation & Trust | Manage internal and external communications transparently to maintain stakeholder and customer confidence. | Collaborating with the Communications Lead to draft a factual statement about the incident for the company website and social media. |
| Ensure Rapid Recovery | Restore affected systems and data efficiently to resume normal business functions as safely and quickly as possible. | Activating a data recovery process from secure, verified backups (e.g., using AWS Backup or Azure Site Recovery) after threat eradication. |
Each of these objectives is interconnected, working in synergy to create a response that is not only technically sound but also strategically intelligent, safeguarding the business from all angles.
Navigating the Six Phases of Incident Response
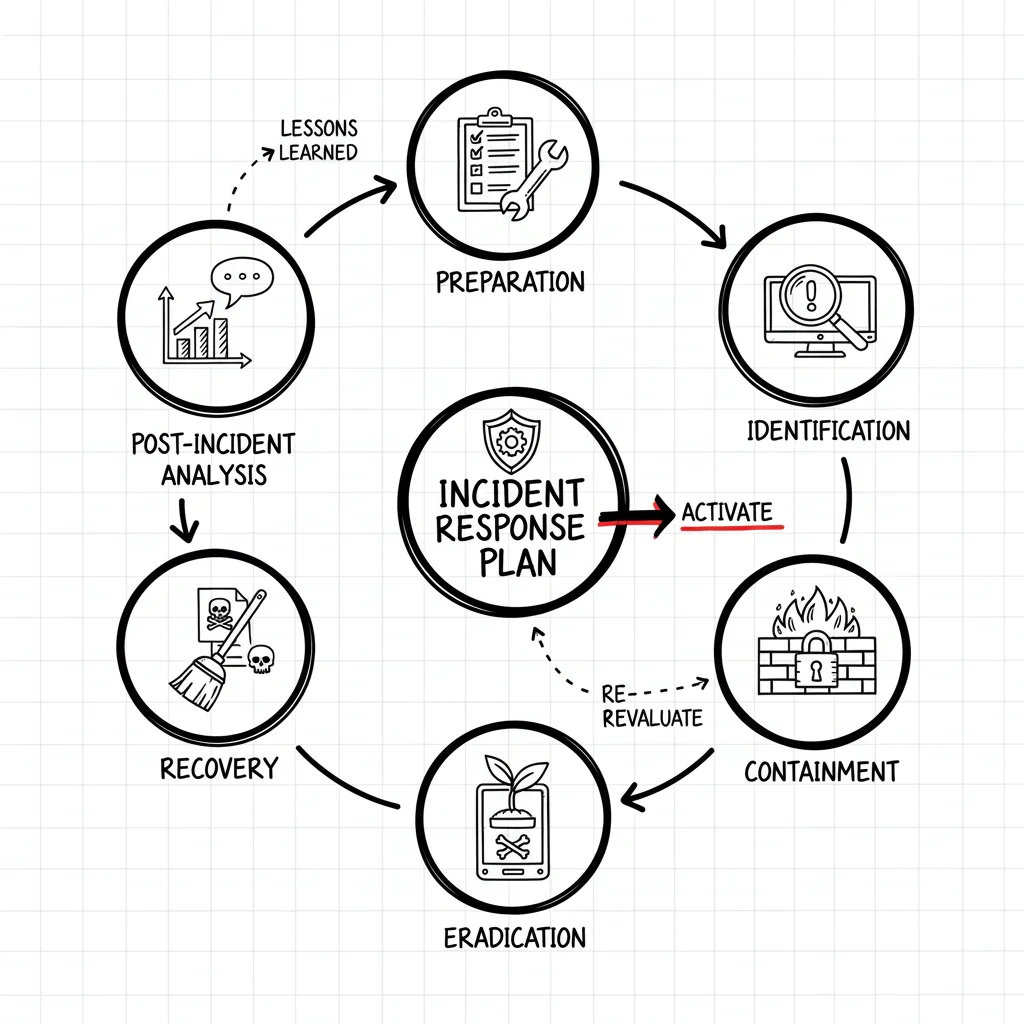
Responding to a security incident isn't a chaotic free-for-all; it's a structured, cyclical process. A robust incident response plan follows a well-defined lifecycle, engineered to guide an organization from the throes of a crisis back to business as usual. This lifecycle, widely adopted and often referenced in certifications like CompTIA Security+ or Certified Information Security Manager (CISM), comprises six distinct phases, each with a critical role.
Consider the analogy of a specialized emergency response for a hazardous chemical spill. You don't just rush in. First, you gather specialized equipment and train your team (Preparation). Then, you precisely identify the chemical, its source, and its immediate danger (Identification). Next, you establish a perimeter and erect barriers to stop the spill from spreading (Containment). Following that, you neutralize and remove the hazardous material entirely (Eradication). Once the area is safe, you clean up and restore it for normal use (Recovery). Finally, you conduct a thorough review to understand what happened and implement measures to prevent future spills (Lessons Learned).
This infographic visually represents how an incident response plan's core objectives steer the entire process, emphasizing minimizing fallout, protecting assets, and achieving quick recovery.

As depicted, the entire cycle focuses on mitigating the impact, safeguarding crucial assets, and restoring operational normalcy with efficiency.
Phase 1: Preparation
This initial phase is, unequivocally, the most vital because it occurs before any incident. Preparation is where your organization builds its digital defenses and meticulously crafts its response playbook. A deficiency here will inevitably compromise the effectiveness of all subsequent phases. For IT professionals, this phase is about proactive security engineering and training, aligning with principles of DevSecOps and ITIL's focus on preventing incidents.
Key activities in this phase include:
- Developing and Documenting the Plan: Creating a comprehensive IRP that details procedures, assigns roles, defines communication channels, and establishes incident severity levels.
- Assembling and Training the Team: Formally establishing an Incident Response Team (IRT) composed of individuals from IT, security, legal, communications, and senior management. This includes cross-training to ensure redundancy and depth of knowledge.
- Acquiring and Configuring Tools: Ensuring the IRT has access to essential security tools like Security Information and Event Management (SIEM) systems, Endpoint Detection and Response (EDR) solutions, network sniffers, forensic toolkits, and secure communication platforms.
- Conducting Regular Training and Drills: Running tabletop exercises and full-blown simulations is crucial. This practical application tests the plan under simulated pressure, ensuring the team is ready to act decisively and efficiently when a real incident strikes.
- Reflection Prompt: When was the last time your team ran a full-scale incident response simulation? What critical gaps were identified and addressed?
Phase 2: Identification
The identification phase commences the instant the first indication of trouble surfaces. The paramount goal is to rapidly and accurately determine if an alert, an anomalous system behavior, or an employee report signals a genuine security incident or is merely a false positive. This phase demands keen analytical skills from security analysts.
This involves sifting through vast amounts of data from diverse sources—network traffic logs, alerts from your SIEM (e.g., Splunk, Microsoft Sentinel), endpoint telemetry from EDR tools, cloud provider logs (e.g., AWS CloudTrail, Azure Monitor), and direct reports from users. The IRT must validate the threat, ascertain its initial scope, and classify its severity. Speed is paramount; studies consistently show that organizations containing a breach faster experience significantly lower costs. For instance, a common statistic cited in CISSP studies highlights that containing a breach in under 200 days can save millions compared to longer response times.
Phase 3: Containment
Once a genuine incident is confirmed, the immediate priority shifts to "stopping the bleeding." Containment strategies are designed to prevent the threat from spreading further and inflicting additional damage across your systems and data. This requires quick, calculated actions.
Containment is about isolation. It’s the digital equivalent of closing fire doors to stop a fire from consuming the entire building. The goal is to limit the blast radius as rapidly as possible.
Tactics may involve short-term measures, such as isolating an infected server from the network, disabling a compromised user account, or blocking malicious IP addresses at the firewall. Long-term containment might involve advanced strategies like micro-segmentation, implementing robust network access control (NAC), or leveraging cloud-native security features (e.g., AWS Security Groups, Azure Network Security Groups) to create secure, isolated zones, a complex topic often explored in advanced cloud security certifications. For a deeper dive into technical containment strategies, you can explore this detailed AWS guide on incident and event response.
Phase 4: Eradication
With the incident successfully contained, the next step is to completely eliminate the threat from your environment. This goes beyond simple removal; it involves thorough root cause analysis to identify and remediate the underlying vulnerabilities that allowed the breach to occur, ensuring the attacker cannot easily regain access. This aligns with ITIL's problem management principles.
Eradication activities typically include:
- Removing Malicious Code: Systematically cleaning or re-imaging compromised systems, removing all malware, backdoors, rogue accounts, and any other artifacts left by the attacker.
- Patching and Remedying Vulnerabilities: Identifying and applying security patches or configuration changes to address the specific weaknesses (e.g., unpatched software, misconfigured firewalls, weak credentials) that facilitated the breach.
- Strengthening Defenses: Implementing enhanced security controls, hardening affected systems, and updating security policies to prevent a recurrence of the same incident type.
Phase 5: Recovery
After the threat has been thoroughly eradicated, the recovery phase focuses on safely bringing affected systems and data back online and restoring normal business operations. This phase demands extreme care to avoid reintroducing vulnerabilities or corrupted data. IT professionals must prioritize data integrity and system stability.
This phase involves restoring systems from clean, verified backups (ensuring they are free of malware), continuous monitoring for any lingering signs of compromise, and systematically bringing services back online. This often involves careful validation testing to confirm functionality and security before full production reintegration. Key metrics like Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are critical considerations here, vital for Business Continuity and Disaster Recovery (BCDR) planning.
Phase 6: Lessons Learned
The final phase, often overlooked but arguably as critical as preparation, involves a comprehensive post-incident review. This is where the IRT and relevant stakeholders conduct a retrospective analysis to meticulously dissect what happened, what aspects of the response worked effectively, and what could have been significantly improved. This feedback loop is absolutely essential for continuous improvement of both security posture and incident response capabilities. Failing to learn from each event means an organization is condemned to repeat the same mistakes, hindering its journey towards greater cyber resilience.
Building the Core of Your Incident Response Plan

While the six phases provide a chronological roadmap for action during a crisis, the true strength and effectiveness of your incident response plan are forged long before any alarm ever sounds. These core components serve as the foundational pillars of your entire security response structure, defining the "who, what, and how" of your operations.
Without these foundational elements, your team is left to improvise, and in high-pressure situations, improvisation frequently leads to errors and inefficiencies. A well-constructed IRP instills order amidst chaos by pre-defining the essential elements that will guide your team toward a successful resolution.
Defining Roles and Responsibilities
When an incident erupts, the last thing any IT professional wants is ambiguity regarding authority or tasks. The most critical component of your plan is the crystal-clear definition of who does what.
This necessitates establishing a dedicated Incident Response Team (IRT) with explicitly assigned duties for each member. An effective IRT is not solely composed of security engineers; it is a cross-functional group capable of handling every facet of an incident, from technical containment and forensic analysis to legal compliance and public relations. Clear roles empower individuals to act swiftly and decisively within their specific areas of expertise.
For IT professionals seeking to build practical, scenario-specific guides for their teams, our article on incident response plan playbooks offers excellent starting points and actionable insights.
A plan without clearly assigned roles is merely a suggestion. During a crisis, suggestions are useless—your team needs direct, unambiguous instructions to follow. Reflection Prompt: Does every member of your team understand their specific role and the critical tasks they own during an incident? How frequently do you review these assignments?
Establishing Communication Protocols
Clear, concise, and calm communication is the absolute lifeline of any incident response effort. A critical question to address is: If your primary communication channels—such as internal email or collaboration platforms like Slack or Teams—are compromised, how will your team communicate securely? Beyond internal dialogue, how will you effectively communicate with external stakeholders?
Your IRP must outline secure, out-of-band communication methods (e.g., encrypted messaging apps, dedicated emergency phone trees, satellite phones) and establish a clear chain of command for information flow. It should answer three fundamental questions:
- Who is authorized to communicate with whom, both internally and externally?
- What channels will be used for internal updates, executive briefings, and public statements?
- What is the core message that needs to be conveyed at each stage of the incident?
Having pre-approved templates for internal alerts, executive summaries, and external public statements can be a lifesaver, ensuring consistent, accurate, and professional messaging throughout the crisis.
Classifying Incident Severity
A sophisticated ransomware attack that cripples your entire production environment cannot be treated with the same urgency as a single employee's laptop infected with low-impact adware. An incident classification system is essential for triaging threats effectively.
This framework helps IT professionals categorize threats, typically using a straightforward scale such as Low, Medium, High, and Critical. This ensures that your team’s most valuable resources—time, technical expertise, and manpower—are concentrated on the most impactful incidents first. It also establishes clear triggers for escalation, informing everyone precisely when senior leadership, legal counsel, or external incident response specialists need to be engaged. For example:
- Critical: Widespread data exfiltration, total system outage for core business functions.
- High: Significant data breach, single critical system compromised, regulatory reporting required.
- Medium: Malware on multiple non-critical endpoints, phishing campaign with limited success.
- Low: Single endpoint virus, policy violation with no immediate threat.
Incident Response Team Roles and Responsibilities
To make the concept of an IRT more tangible, let's detail some of the key roles typically found in a well-structured Incident Response Team. Defining these positions proactively is absolutely essential for a coordinated and effective response.
| Role | Primary Responsibility | Example Task for an IT Pro |
|---|---|---|
| Incident Response Manager | Leads and coordinates the entire response effort, making key strategic and tactical decisions. | Authorizing the shutdown of a critical production system in AWS to contain a rapidly spreading breach. |
| Security Analyst (Tier 1/2/3) | Performs initial investigation, threat analysis, technical containment, and eradication. | Analyzing network logs and EDR telemetry to identify the source and lateral movement of a malicious connection. |
| Forensics Investigator | Collects and preserves evidence, conducts in-depth analysis to determine attack vectors and impact. | Creating disk images of compromised servers and analyzing memory dumps to identify attacker tools and techniques. |
| Communications Lead | Manages all internal and external messaging to stakeholders, media, and customers. | Drafting and coordinating the release of a public data breach notification statement in compliance with regulatory mandates. |
| Legal Counsel | Advises on regulatory compliance, evidence preservation, and potential legal liabilities. | Ensuring the incident response actions comply with GDPR's 72-hour breach reporting rule or HIPAA's notification requirements. |
| Senior Business Leader | Provides executive oversight, makes high-level business decisions regarding operational impact and recovery priorities. | Approving budget for emergency software licenses or external forensic support. |
Each role is a critical piece of the puzzle. When every team member fully understands their part, the IRT can function as a cohesive and efficient unit, even under the most intense and stressful conditions.
Why Plan Testing Is Your Best Investment

An incident response plan that merely exists as a static document gathering dust on a shared drive is little more than a theoretical exercise. A battle-tested, continuously refined plan, however, represents a significant competitive advantage and a cornerstone of organizational resilience. This is where many organizations falter—they invest in creating a plan but then skip the single most important step: rigorously testing it through regular drills and simulations.
Consider a professional sports team. They don't just read their playbook and expect to perform flawlessly. They run drills repeatedly until every movement, every coordination, becomes muscle memory. This is precisely what regular testing accomplishes for your incident response team. It builds confidence, sharpens coordination, and ingrains the necessary muscle memory for a rapid and effective response when a real incident inevitably occurs.
From Theory to Practice: Uncovering Real-World Gaps
Testing isn't about achieving a perfect score; it's about crucial discovery. It provides a safe, controlled environment to uncover the hidden cracks in your strategy, your processes, and your technology before they manifest during a live crisis. Perhaps you discover that your "secure" out-of-band communication channel fails under simulated network stress, or a critical team member lacks the necessary access privileges to perform their assigned duties in a lockdown scenario.
Identifying and rectifying these gaps during a controlled drill means you can reinforce your defenses and refine your procedures before a real cyberattack hits. This transforms plan testing from a mere compliance chore into a high-return investment in your organization's ability to swiftly recover from any disruption. It conditions your team to perform with precision and composure when the stakes are highest and every second counts. This proactive approach is a hallmark of leading security frameworks and certifications like NIST Cybersecurity Framework and CISM.
The real value of testing an incident response plan is finding out what breaks when the stakes are low, so you can ensure it holds strong when they're high.
This isn't just a hypothetical benefit; it has a profound financial impact. A surprising 30% of organizations reportedly do not conduct regular plan testing. Yet, companies that actively test their IRPs save an average of $1.49 million per breach compared to those that don't. If you wish to delve deeper into this critical gap in preparedness, you can explore the latest incident response statistics over at JumpCloud.
Common Testing Methods for IT Teams
You don't need to jump immediately into massive, complex live-fire exercises. There's a spectrum of testing methods, allowing you to choose the most appropriate one based on your team's maturity, available resources, and specific objectives. The goal is continuous improvement and maintaining plan relevance.
- Tabletop Exercises: These are guided discussions where your response team convenes to walk through a simulated incident scenario, verbally discussing their decisions, actions, and communication steps. They are a fantastic, low-cost way to verify if communication protocols are understood, if roles are clear, and if the documented procedures are logical. Ideal for initial plan validation and team training.
- Walkthroughs: A step up from tabletops, walkthroughs involve each team member physically going through a specific scenario, explaining their exact actions step-by-step using actual tools and interfaces (though not executing live commands). This method is excellent for verifying the clarity and accuracy of documented procedures and identifying practical limitations.
- Full-Scale Simulations: This is the most realistic form of testing—a live drill that mimics an actual attack as closely as possible within a safe, isolated environment. It tests everything: your people, your processes, and your technology, all under realistic pressure. This method provides invaluable insights into system performance under duress, team coordination, and the effectiveness of security controls.
Understanding Global Gaps in Cyber Readiness
Having a well-documented incident response plan is a critical internal achievement, but its real-world effectiveness is heavily influenced by a much broader context. Incident response isn’t merely a challenge for an individual company; it is a pervasive global issue, and the reality is that preparedness levels vary dramatically across sectors and regions.
When we zoom out, we observe a fragmented landscape of cyber readiness. This imbalance creates a fragile ecosystem where a significant weakness in one sector can rapidly escalate and impact others. The disparity in preparedness between the private and public sectors, particularly critical infrastructure, is often a glaring concern for IT security professionals.
The Public and Private Sector Divide: A Critical Concern
Recent analyses consistently highlight a worrying trend: critical infrastructure (e.g., energy, water, transportation) and public services often lag behind their private-sector counterparts in terms of cyber resilience. For example, some reports indicate that the public sector is disproportionately affected, with a higher percentage of respondents acknowledging insufficient resilience compared to medium-to-large private-sector organizations. To genuinely bridge these gaps, it's paramount to embed robust compliance security in business processes directly into the foundation of any defense strategy.
This divide isn't solely attributable to disparities in funding or technology; it's profoundly linked to human capital. The same analyses frequently reveal that nearly half of public-sector organizations struggle with a lack of skilled cybersecurity talent required to achieve their security objectives. A skilled workforce is the backbone of any effective incident response plan, and without it, even the most meticulously crafted plans are prone to failure. For comprehensive insights, you can review the details in the latest global cybersecurity outlook report from the World Economic Forum.
The readiness of our most critical services—from utilities to government agencies—is directly tied to the availability of a skilled cyber workforce. A talent shortage in one sector weakens the security fabric for all.
Why This Broader Context Matters to Your Organization
So, why is this wider perspective crucial for you and your organization? Because no business operates in isolation. Your organization's security posture is inextricably linked to that of your partners, your supply chain, and the essential public infrastructure you rely on daily. A significant vulnerability or a successful attack against a local utility provider or a key government agency could quickly cascade into your next major incident.
This broader context underscores the collective responsibility and highlights several key imperatives:
- Investing in Workforce Development: It's imperative to collectively address the cybersecurity talent gap through sustained investment in training, education, and professional development programs, which is where certifications play a huge role.
- Promoting Public-Private Partnerships: Collaborative efforts are vital. When sectors share threat intelligence, best practices, and resources, the entire cyber ecosystem becomes more resilient and capable of resisting sophisticated attacks.
- Prioritizing Critical Infrastructure Security: Securing essential services is not solely a government responsibility. It is a shared imperative that safeguards our collective digital future and ensures the foundational services upon which all businesses depend remain operational.
Your Incident Response Plan Questions Answered by Experts
As IT professionals embark on the journey of developing or refining their organization's Incident Response Plan (IRP), several practical questions invariably emerge. This section bridges the gap between theoretical knowledge and real-world application. Let's address some of the most common inquiries regarding the effective implementation and maintenance of an IRP.
How Often Should an IRP Be Updated?
Consider your incident response plan a living, dynamic document, not a static file to be created once and then forgotten. At a minimum, your IRP should undergo a full review and update at least once a year. However, certain trigger events should necessitate an immediate review and revision:
- After Any Security Incident: Each incident, regardless of its severity, provides invaluable lessons. Integrate these lessons learned—what worked, what failed, and what unexpected challenges arose—directly back into the plan.
- Following Major IT or Business Changes: Significant shifts in your IT infrastructure (e.g., migrating to a new cloud provider like Azure or Google Cloud, implementing new enterprise software, network overhauls), or changes in business processes, can introduce new vulnerabilities or alter response procedures.
- When Key Personnel Changes: If core members of your Incident Response Team leave or new roles are created, the plan must be updated to reflect new names, roles, contact information, and responsibilities.
- When New Threats Emerge or Regulations Change: The threat landscape is constantly evolving with new attack vectors and malware. Similarly, new data privacy laws or industry regulations (e.g., updates to ISO 27001 or NIST guidelines) may mandate changes to your response protocols.
Regular drills, such as quarterly tabletop exercises, are excellent for proactively identifying gaps or areas for improvement that should prompt immediate plan adjustments. An outdated plan provides a false sense of security and can lead to ineffective responses during a real crisis.
IRP vs. Disaster Recovery Plan (DRP): What's the Difference?
This is a classic point of confusion, yet the distinction is crucial for IT professionals. While an IRP and a DRP are closely related and must work in concert, they serve fundamentally different purposes within a broader Business Continuity Plan (BCP).
An Incident Response Plan (IRP) is tactical and immediate. It's the playbook for dealing with a specific security event, such as a ransomware attack, a data breach, or a denial-of-service (DoS) attack. Its primary purpose is to contain the threat, eradicate it, and recover affected systems back to a secure state. Think of the IRP as the cybersecurity equivalent of the firefighters battling a blaze.
A Disaster Recovery Plan (DRP) is strategic and broader in scope. It's the blueprint for restoring critical IT infrastructure and business operations after any major disruption. While a cyberattack can trigger a DRP, it also covers non-cyber disasters like natural calamities (floods, earthquakes), massive power outages, or physical infrastructure failures. The DRP focuses on getting the entire business back online—the IRP fights the fire, and the DRP rebuilds and restores the building. They are complementary; an IRP often precedes and informs DRP activation in cyber-related disasters.
Who Should Be on the Incident Response Team?
An truly effective Incident Response Team (IRT) is never solely composed of the IT department. While technical staff form the operational core, a crisis demands a diverse blend of skills and perspectives from across the business to ensure well-rounded, strategic decision-making.
Your IRT should absolutely include people with expertise from:
- IT and Security Operations: These are your technical front-liners—security analysts, network engineers, system administrators, and forensic specialists—who investigate, contain, eradicate, and recover.
- Legal Counsel: Essential for guiding the team through the complex landscape of regulatory compliance (e.g., GDPR, HIPAA), legal liabilities, evidence preservation, and potential litigation.
- Communications/Public Relations: Responsible for crafting and disseminating internal and external messages to employees, customers, partners, and the media. This role is critical for protecting the organization's reputation.
- Human Resources (HR): Steps in to manage any employee-related issues, such as compromised employee accounts, potential insider threats, or providing support to affected staff.
- Senior Leadership/Management: A representative with authority to make high-level business decisions, allocate emergency resources, and provide strategic direction, especially when operational impact is severe.
- Business Unit Representatives: Individuals who understand the critical processes and data within their respective business units, helping to prioritize recovery efforts based on business impact.
This interdisciplinary blend ensures that during an incident, not only are the technical problems addressed, but also the legal, reputational, human resource, and strategic business implications are managed holistically.
Can a Small Business Have an Effective IRP?
Absolutely—and in today's threat landscape, small businesses critically need one. Cybercriminals often perceive small and medium-sized businesses (SMBs) as easier targets due to potentially fewer resources and less mature security postures. Therefore, an IRP is not a luxury for large enterprises but a vital survival tool for SMBs.
The good news is that an IRP for a small business can be simpler and more focused. It doesn't need to be a 100-page tome. It just needs to cover the core essentials:
- Defined Roles (even if one person wears multiple hats): Who does what, even if it's the owner, a key IT person, and an outsourced IT consultant.
- Key Contacts: A clear list of internal and external contacts (e.g., IT support vendor, legal counsel, insurance provider, local FBI cyber task force).
- Basic Communication Steps: How to notify affected parties internally and externally.
- Procedure for Common Threats: A simplified, clear procedure for prevalent threats like ransomware, phishing, or data loss.
- Backup and Recovery Strategy: Most importantly, a tested process for restoring data from secure backups.
Numerous free templates and resources are available from trusted sources like NIST (National Institute of Standards and Technology) that small businesses can adapt. The most critical aspect is having a documented, accessible plan before a crisis hits. Attempting to create one amidst the chaos of an active incident is a recipe for disaster.
MindMesh Academy is your dedicated partner in building the essential skills required to protect your organization's digital assets. Our expert-led certification prep courses in critical domains like CompTIA Security+ and AWS Security provide the deep knowledge and practical strategies necessary to design, implement, and execute highly effective security programs and incident response frameworks. Empower yourself with in-demand expertise and become an indispensable security leader. Start your learning journey today at https://mindmeshacademy.com.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 15 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.