Problem Management vs Incident Management: Complete Guide
Incident Management vs. Problem Management: A Comprehensive Guide for IT Professionals
In the dynamic world of IT service management (ITSM), distinguishing between incident management and problem management is crucial for operational excellence and strategic growth. While often confused due to their shared goal of service stability, they serve fundamentally different purposes. Simply put, incident management is reactive, focused on quickly restoring a disrupted service. In contrast, problem management is proactive, dedicated to identifying and eliminating the underlying root causes of incidents to prevent their recurrence.
Consider this classic analogy: Incident management is akin to the fire department rushing to extinguish a blaze, minimizing immediate damage. Problem management, on the other hand, embodies the fire marshal investigating the cause after the fire is out, aiming to implement preventative measures so such an event never happens again. For IT professionals pursuing certifications like ITIL, CompTIA, or even PMP, a clear understanding of these distinct yet interdependent disciplines is foundational.
Understanding The Core Difference
 Caption: Incident Management (left) focuses on immediate crisis, while Problem Management (right) tackles the underlying cause.
Caption: Incident Management (left) focuses on immediate crisis, while Problem Management (right) tackles the underlying cause.
Within the broader framework of ITSM, these two disciplines have distinct missions. Incident management prioritizes speed and efficiency, striving to return services to normal operation with the least possible disruption. Its success is measured by how swiftly an outage or degradation is resolved, directly impacting user satisfaction and adherence to Service Level Agreements (SLAs).
Problem management, however, takes a more deliberate, long-term approach. It steps back from the immediate crisis to investigate the why behind recurring or major incidents. Its goal isn't a quick fix, but a permanent solution that enhances the overall stability, resilience, and performance of IT services. This strategic focus is essential for reducing technical debt and improving system reliability over time.
Let's illustrate with a common scenario: an e-commerce platform experiences intermittent crashes during peak shopping events.
-
Incident Management in Action: The on-call operations team receives an alert indicating a critical service interruption. Their immediate focus is on restoring the website right now. This might involve restarting server instances (common in AWS or Azure environments), rolling back a recent code deployment, or rerouting traffic. The success of this response is primarily measured by Mean Time To Resolve (MTTR)—how quickly the site is brought back online.
-
Problem Management in Action: After this critical crash occurs for the third time in a month (representing three distinct incidents), a problem record is formally opened. The problem management team shifts gears from reactive restoration. They meticulously analyze server logs, performance metrics, and application traces, looking for patterns or anomalies that indicate the root cause. This deep dive might involve collaborating with development teams to review code, or infrastructure teams to scrutinize network configurations.
In this example, the investigation reveals a subtle memory leak within a newly deployed feature, only triggered under heavy user load. The problem team then coordinates a permanent fix—developing, thoroughly testing, and deploying a code patch. This ensures the specific crash never recurs, preventing future revenue loss and preserving customer trust.
For IT professionals preparing for ITIL certifications, understanding how these processes integrate into a holistic service management strategy is key. You can learn more about where these fit in our guide on What is ITIL Service Management Explained.
Key Takeaway: Incident management fixes the symptom (e.g., "the website is down"), while problem management cures the disease (e.g., "the underlying memory leak that causes the website to crash").
Incident Management vs Problem Management At a Glance
To make the distinction crystal clear, examining their core attributes side-by-side proves invaluable. This table offers a concise snapshot of their differing goals, focus, and typical activities.
| Attribute | Incident Management | Problem Management |
|---|---|---|
| Primary Goal | Restore service immediately | Prevent incidents from recurring |
| Focus | Reactive; speed and efficiency | Proactive; analysis and prevention |
| Timeline | Short-term; immediate response | Long-term; ongoing investigation |
| Core Activity | Triage, diagnosis, and resolution | Root Cause Analysis (RCA) |
Ultimately, neither discipline can operate effectively in isolation. A mature IT organization, often guided by frameworks like ITIL 4, skillfully balances the urgent need for service restoration with the strategic imperative of preventing future disruptions. This balance is crucial for maintaining both short-term stability and long-term operational resilience.
Comparing Strategic Goals and Business Impact
While both incident and problem management contribute to service stability, their strategic goals operate on different timelines with distinct business impacts. Incident management serves as the organization's frontline defense—tactical, immediate, and singularly focused on maintaining current operations.
Its primary objective is to resolve service disruptions as quickly as possible, minimizing the damage. Every minute of downtime translates into potential financial loss, erosion of customer trust, and even breaches of contractual Service Level Agreements (SLAs). For professionals in roles such as a Project Manager (PMP certified) or a Cloud Architect (AWS/Azure certified), understanding this immediate impact is critical for risk assessment and business continuity planning. The strategic value of incident management is clear: protecting immediate revenue streams and operational integrity.
Problem management, conversely, plays a pivotal long-term role. It moves beyond quick fixes to ensure that the same issues do not repeatedly surface. By rigorously investigating and eliminating root causes, the goal is to systematically reduce the volume and severity of recurring incidents over time. This shifts the organization from a perpetual state of "firefighting" to a proactive stance of "fireproofing" its services. This builds inherent operational resilience, a key strategic advantage for any IT-dependent business.
This infographic effectively illustrates the symbiotic relationship between these two functions:
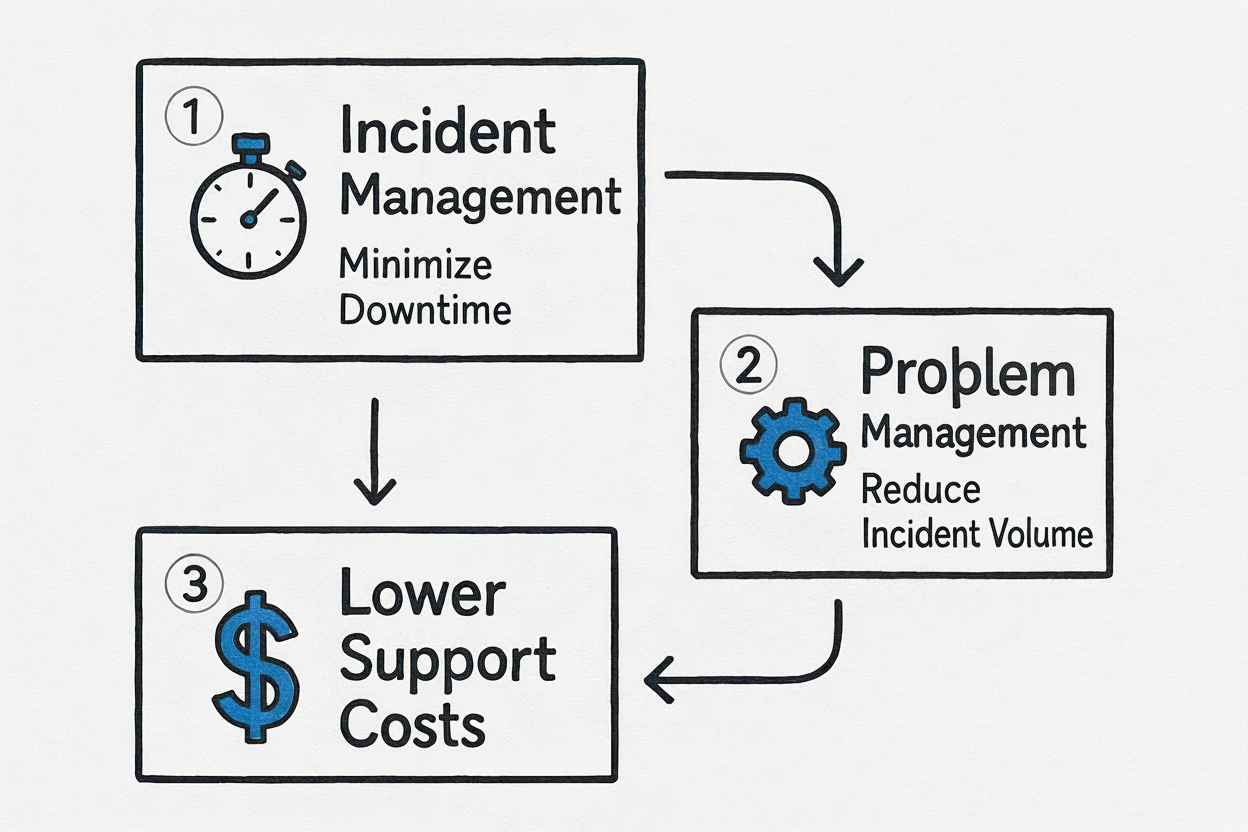 Caption: The strategic flow from immediate incident resolution to long-term problem prevention, leading to significant cost savings.
Caption: The strategic flow from immediate incident resolution to long-term problem prevention, leading to significant cost savings.
As the visual indicates, containing immediate damage is incident management's primary role. However, it is problem management that cultivates lasting value by breaking the cycle of reactive fixes and driving down long-term support and operational costs.
The Shift from Reactive to Proactive Value
Grasping this fundamental distinction is essential for IT leaders to justify budgets, allocate resources, and demonstrate tangible value. The impact of incident management is often immediate and easily quantifiable. Metrics such as Mean Time To Resolve (MTTR) directly illustrate how rapidly services are restored, effectively stemming financial losses.
The business impact of problem management is less dramatic in the short term but arguably more profound over time. It systematically delivers:
- Reduced Support Costs: Fewer recurring incidents mean your IT teams spend less time on reactive troubleshooting and more time on strategic initiatives or development work.
- Increased System Reliability: By eliminating underlying flaws, services become inherently more stable, predictable, and available. This significantly boosts user satisfaction and organizational trust.
- Prevention of Major Outages: Often, a single unresolved problem can be the latent cause behind numerous smaller incidents. Proactively identifying and fixing it can avert a catastrophic system failure or data breach.
Frameworks like ITIL (Information Technology Infrastructure Library) deliberately separate these two functions. As outlined in the ITIL 4 guidelines, maintaining distinct processes prevents the natural tendency to prioritize a quick workaround over a permanent solution. This structured approach ensures organizations are not sacrificing long-term service health for short-term stability. You can dig deeper into these practical ITIL guidelines to see how they apply in various organizational contexts. For comprehensive study materials on ITIL, MindMesh Academy offers expert-curated content designed for certification success.
Key Insight: Incident management safeguards current business operations, while problem management cultivates and secures business resilience for the future.
A solid grasp of the distinct goals and impacts of problem management versus incident management is instrumental for building a robust and cost-effective IT service model. One manages the present, ensuring continuity; the other meticulously builds a more stable—and ultimately less expensive—future.
A Tale of Two Playbooks: Workflows and Processes
 Caption: Incident Management follows a rapid, linear path, while Problem Management embarks on a cyclical, in-depth investigation.
Caption: Incident Management follows a rapid, linear path, while Problem Management embarks on a cyclical, in-depth investigation.
To truly appreciate the operational differences between problem and incident management, it's essential to examine their respective workflows. Each possesses a unique "playbook" meticulously designed for its specific purpose: one optimized for speed, the other for depth.
Think of the incident management process as a high-stakes sprint, driven by the urgency of restoring service. In contrast, the problem management process resembles a methodical, often iterative, detective's investigation. This isn't merely a minor difference in approach; it defines their very nature. Incident management aims to get systems operational now, whereas problem management is engineered to pause, meticulously investigate, and fundamentally understand why failures occur.
The Incident Management Lifecycle: A Race Against the Clock
When a service disruption occurs, the incident management workflow immediately activates. This process is inherently reactive and singularly focused on speed. Every second of downtime can translate into lost revenue and user frustration, making time the primary driver. The process initiates the moment a service disruption is detected.
From that point, it follows a rapid, streamlined sequence:
- Detection and Logging: An incident is identified, perhaps via an automated monitoring alert (common in cloud environments like AWS CloudWatch or Azure Monitor), a user report, or a service desk call. It's immediately logged into an ITSM system, capturing initial details and establishing a single source of truth.
- Categorization and Prioritization: The incident is classified (e.g., "network outage," "application error," "security breach") and assigned a priority based on its business impact and urgency. A critical system failure affecting key business functions (Priority 1) will trigger an immediate, all-hands-on-deck response, while a minor cosmetic issue can be scheduled.
- Initial Diagnosis: Front-line support teams perform a quick assessment to understand the immediate symptoms. The objective is rapid identification of a known workaround or a straightforward fix, not an exhaustive root cause analysis. This phase often utilizes diagnostic skills emphasized in CompTIA A+ or Network+ certifications.
- Escalation (If Needed): If the initial diagnosis proves insufficient, or the incident's complexity warrants, it's escalated to specialized teams—such as database administrators, network engineers, or application developers—who possess the deep expertise required for resolution.
- Resolution and Recovery: The team implements a fix to restore the service. This could range from a simple server reboot, a configuration rollback, or applying a documented workaround. The emphasis is purely on restoring functionality.
- Closure: Once the service is confirmed stable and operational, and affected users confirm resolution, the incident ticket is formally closed.
The entire lifecycle is centered on containment and rapid restoration. To see this in more detail, our study guide on the ITIL 4 Foundation: Incident Management offers a complete breakdown of this critical process, a must-read for anyone pursuing ITIL certification.
The Problem Management Workflow: An Investigative Journey
Problem management often commences where incident management concludes, particularly when incidents are severe, repetitive, or indicative of deeper systemic flaws. This is a significantly more proactive and analytical process, squarely focused on preventing future outages rather than merely fixing current ones. The intense time pressure characteristic of incident management is largely absent here.
The core of problem management is shifting the organizational mindset from "What broke and how do we fix it now?" to "Why did it break and how do we stop it from ever breaking again?"
The problem management workflow is structured much like a detailed forensic investigation:
- Problem Detection: A problem is formally identified, typically by analyzing trends in past incidents. For example, if a specific server crashes five times within a month, it's no longer just a series of individual incidents; it's a systemic problem demanding investigation. Proactive monitoring tools can also flag potential problems before they manifest as incidents.
- Problem Logging and Categorization: A dedicated problem record is created, consolidating all related incident tickets. This provides the investigation team with comprehensive data and context in one central location.
- Root Cause Analysis (RCA): This is the heart of problem management. The team employs various analytical techniques such as the "5 Whys," Ishikawa (fishbone) diagrams, or Fault Tree Analysis to delve past superficial symptoms and uncover the fundamental cause. This phase requires strong analytical and logical reasoning skills, highly valued in certifications like PMP or advanced ITIL modules.
- Identifying a Workaround: While the team develops a permanent solution, they identify and document a temporary workaround. This is invaluable for the incident team, enabling them to resolve any new, related incidents much faster and consistently.
- Creating a Known Error Record: Once the root cause is confirmed and a reliable workaround is established, a Known Error record is created and stored in the Known Error Database (KEDB). This repository becomes a vital knowledge base, empowering the entire service desk and improving resolution times for future incidents.
- Implementing a Permanent Fix: Finally, the problem team collaborates with relevant stakeholders (e.g., development, operations, security) to design, test, and deploy a permanent solution that eradicates the root cause. This typically integrates with a formal change management process, ensuring controlled and successful implementation.
Figuring out how to streamline these different operations is crucial for overall ITSM maturity. By distinguishing between these two distinct workflows, organizations can address the immediate needs of service restoration while simultaneously building a more resilient future.
Comparing Roles and Required Skill Sets
 Caption: Different mindsets and skills define the distinct roles in incident (left) and problem (right) management.
Caption: Different mindsets and skills define the distinct roles in incident (left) and problem (right) management.
Any highly effective IT process is fundamentally driven by the people executing it. When examining incident versus problem management, the clearest distinctions often arise from the teams themselves. Their daily focus, core competencies, and even their psychological makeup differ significantly because their overarching missions are fundamentally distinct.
Consider this: Incident management teams function as the organization's first responders. They thrive under intense pressure, their performance primarily measured by their speed, decisiveness, and ability to mitigate immediate impact. Problem management teams, conversely, are the meticulous investigators, valued for their analytical rigor, persistence, and ability to uncover root causes.
The Frontline Responders in Incident Management
Roles within incident management are entirely focused on immediate action, rapid coordination, and clear communication. These are the professionals who confront critical situations head-on, excelling in high-stakes environments where quick thinking directly impacts business continuity.
- Service Desk Analyst: This is often the first point of contact for users experiencing issues. They are masters of triage, responsible for logging incidents, performing initial diagnostics (drawing upon skills learned in CompTIA A+ or similar foundational certifications), and attempting immediate resolution. Their communication skills are paramount—they must calmly gather information from potentially frustrated users while relaying critical details to technical teams.
- Incident Manager: For major incidents or widespread outages, the Incident Manager assumes command. This role is less about hands-on technical fixes and more about orchestration, leadership, and crisis communication. They act as the central hub, ensuring effective coordination among diverse teams, removing roadblocks, and keeping all stakeholders (from executive leadership to affected users) informed. This role demands exceptional crisis management, assertive communication, and the fortitude to make rapid, critical decisions under pressure, much like a project manager navigating an urgent project deviation.
These roles are, by their very nature, reactive. Their singular focus is getting services back to normal as rapidly as possible.
Key Insight: An Incident Manager's primary objective is to restore service by any viable means necessary, often prioritizing a temporary workaround over an immediate permanent fix. They manage the immediate crisis, not necessarily the underlying cause.
The Deep Divers in Problem Management
Problem management requires a distinct professional profile—individuals who are patient, methodical, and profoundly analytical thinkers. Their success is not gauged by minutes to closure, but by the long-term stability and inherent resilience they embed within the IT ecosystem.
Here are the key players in this investigative process:
- Problem Manager: This individual owns the entire lifecycle of a problem, from its initial identification to the successful deployment of a permanent fix. The Problem Manager leads Root Cause Analysis (RCA) sessions, ensures the documentation of known errors for the service desk, and collaborates with development or infrastructure teams to deploy lasting solutions. They require sharp analytical skills, a keen ability to identify patterns in incident data, and the persistence to navigate complex investigations to completion—qualities highly valued in advanced ITIL or PMP contexts.
- Subject Matter Experts (SMEs): A Problem Manager rarely operates in isolation. They rely heavily on SMEs—senior engineers, system architects, or developers—who possess deep technical knowledge of the systems under investigation. These experts provide the technical horsepower necessary to diagnose intricate root causes, validate potential solutions, and ensure that proposed fixes are robust and effective. For example, an AWS Solutions Architect SME might pinpoint a misconfigured auto-scaling group as the root cause of an intermittent performance problem.
To highlight the distinction, let's compare the two lead roles directly:
Role Comparison: Incident Manager vs. Problem Manager
This table clearly delineates the core differences in responsibilities and requisite skills, illustrating how each role is precisely tailored to the unique goals of its respective discipline.
| Aspect | Incident Manager | Problem Manager |
|---|---|---|
| Primary Focus | Command and control during a live incident. | Investigation and prevention of future incidents. |
| Key Responsibility | Coordinate real-time resolution efforts. | Facilitate Root Cause Analysis (RCA). |
| Core Competency | Crisis management and rapid decision-making. | Analytical thinking and pattern recognition. |
| Measure of Success | Keeping Mean Time to Resolve (MTTR) low. | Reducing the rate of recurring incidents. |
Ultimately, a truly mature IT operation cannot thrive without both roles. The incident management team acts as the crucial guardian of business continuity today, while the problem management team meticulously secures the organization's stability and reliability for tomorrow.
Measuring Success with the Right KPIs
As the adage goes, "You can't improve what you don't measure." To ascertain the effectiveness of your problem and incident management processes, leveraging appropriate Key Performance Indicators (KPIs) is paramount. The metrics for each discipline are as distinct as their core missions.
For incident management, the central question is always: "How swiftly and effectively did we restore service?" This process is entirely predicated on speed and efficiency under duress. Consequently, its KPIs are direct reflections of that urgent, reactive focus, often critical for meeting SLAs and maintaining business operations.
Problem management, in contrast, asks a fundamentally different question: "How successfully are we preventing future problems from occurring?" Success here is not measured in minutes, but in sustained long-term stability and a tangible reduction in operational risk. Its KPIs track the progress toward cultivating a calmer, more resilient IT environment.
Incident Management KPIs: Gauging Speed and Restoration
The metrics for incident management are predominantly time-based. They provide a quantitative assessment of how well the team contains damage and minimizes downtime, which directly correlates with user satisfaction and business continuity. These are frequently reported in IT operations and are often topics covered in ITIL Foundation or CompTIA Server+ exams.
Key metrics to monitor:
- Mean Time to Resolve (MTTR): This is the quintessential incident management KPI. It calculates the average time from an incident's logging until its complete resolution, offering a clear measure of team efficiency and restoration speed.
- First Call Resolution (FCR) Rate: This metric indicates the percentage of incidents resolved by the service desk during the initial contact, without requiring escalation. A high FCR rate signifies a highly capable front-line team with effective tools and knowledge.
- SLA Compliance Rate: This critical KPI measures how often incidents are resolved within the timeframes stipulated in your Service Level Agreements. Consistently missing these targets can incur financial penalties, damage reputation, and erode stakeholder trust.
These KPIs are acutely focused on the immediate "now." They narrate a story of current operational performance, demonstrating to stakeholders precisely how quickly the organization can recover when disruptions inevitably occur.
Problem Management KPIs: Tracking Prevention and Stability
While incident metrics emphasize speed, problem management KPIs are fundamentally about prevention and strategic improvement. These figures demonstrate your team's proficiency in uncovering and eliminating the root causes of persistent, disruptive issues. The overarching objective is to forge a more stable, predictable service environment over the long haul. This aligns with the continuous improvement principles emphasized in ITIL.
Key Takeaway: The ultimate goal of problem management is to render itself redundant for a specific issue by ensuring it never recurs. Robust KPIs are how you objectively validate this long-term value.
Core KPIs for problem management include:
- Reduction in Recurring Incidents: This is arguably the most impactful KPI. It directly quantifies success by tracking the measurable decrease in incidents linked to a specific problem that has been formally "solved." This can be broken down by service, application, or even specific infrastructure components.
- Number of Known Errors Documented: This KPI tracks new additions to your Known Error Database (KEDB). A consistent flow here indicates that the problem team is effectively identifying root causes and formalizing practical workarounds for the incident team to utilize, significantly improving future incident resolution efficiency.
- Root Cause Identification Success Rate: This measures the percentage of problem investigations that successfully pinpoint a verifiable root cause. A high success rate underscores your team's deep analytical capabilities and effectiveness in tackling complex technical challenges.
What should IT professionals aim for? Industry benchmarks provide valuable targets. High-performing organizations often achieve a MTTR under 30 minutes for critical incidents. For problem management, leading organizations strive for a repeat incident rate below 2-5% and a root cause identification rate exceeding 80%. Understanding and striving for these benchmarks can significantly elevate an organization's IT service maturity.
How They Work Together in Real Scenarios
*Caption: A video explaining the practical differences and symbiotic relationship between incident and problem management.*While the theoretical definitions of problem and incident management are important, their true value becomes apparent when observing them working in concert. This synergy represents a carefully choreographed dance between reactive firefighting and proactive prevention, essential for resilient IT operations.
Let's explore two real-world scenarios to illuminate this crucial partnership. The first depicts a high-stakes emergency that every digital business hopes to avert. The second illustrates a more subtle, simmering issue that could easily be overlooked without a robust problem management function.
Scenario One: The Major E-Commerce Outage
It's the busiest sales event of the year for a global online retailer. Precisely at the peak of customer traffic, the entire website becomes inaccessible. Alarms blare, and with every passing minute, thousands of dollars in revenue are lost, along with customer trust.
The Incident Management Response: The incident management team immediately springs into action. Their singular, overriding objective is to restore service—now.
- An Incident Manager quickly establishes a high-priority "war room" communication channel, bringing together key technical personnel.
- Engineers rapidly diagnose that the application servers are completely unresponsive, possibly due to resource exhaustion or a critical application error.
- The fastest path to recovery is identified as a full reboot of the primary server cluster and a rollback to a previously stable deployment.
- Service is successfully restored within 15 minutes. The incident is officially closed, and business operations resume, mitigating significant financial impact.
The incident team performed flawlessly, extinguishing the immediate crisis. However, the critical question of why the outage occurred remains unanswered, leaving the business vulnerable to a repeat failure.
This swift, decisive response exemplifies incident management—containing immediate damage to protect the business. Yet, without subsequent problem management, the organization remains susceptible to the exact same, potentially more severe, future disruptions.
The Problem Management Investigation: A few hours later, once the immediate chaos of the sales event has subsided, the problem management team initiates its work. They open a new problem record, linking it directly to that major incident. Their approach is diametrically opposed to the incident team's: it is slow, methodical, and deeply analytical, often involving techniques taught in ITIL Problem Management training.
- They begin by meticulously sifting through server logs, application metrics, and network traffic data from the precise moments leading up to and during the crash.
- They correlate event timestamps with known changes, database queries, and system resource utilization.
- After several days of careful investigation and collaboration with database and development teams, they uncover the root cause: an inefficient database query, part of a newly deployed recommendation engine, was exhausting the database connection pool under extreme load, causing the application servers to lock up.
With the "why" definitively identified, the final step involves implementing a permanent solution. The problem team collaborates with developers to optimize the database query, reconfigure connection pool settings, and deploy a robust patch. This change hardens the platform, ensuring it can gracefully handle future traffic spikes without crashing, effectively preventing a recurrence of such an expensive outage.
Scenario Two: The Recurring Slow Performance Complaints
Now, consider a less dramatic but equally frustrating and insidious issue. For several weeks, the service desk has received a steady trickle of tickets from users complaining that a key internal financial application is "slow" or "laggy," particularly during afternoon hours.
The Incident Management Response: For each individual ticket, the service desk analyst follows their standard troubleshooting playbook:
- They instruct the user to clear their browser cache, restart their workstation, or check their network connection.
- In some cases, the issue appears to resolve itself temporarily, and the incident ticket is closed with a "user error" or "system transient" resolution.
Individually, each incident is perceived as minor and quickly "resolved." From a purely incident-focused perspective, the operational metrics appear satisfactory. However, the larger, more dangerous underlying pattern is being completely overlooked, slowly eroding user productivity and satisfaction. For a deeper look into how these processes should interact, you can explore detailed ITIL workflows in motion through MindMesh Academy's study guides.
The Problem Management Investigation: A vigilant Problem Manager, reviewing incident trends, notices the recurring pattern. Over the last month, 15 separate incidents were logged for the same application, all reporting "slowness" during specific times. This recurring pattern triggers a formal problem investigation, a clear example of proactive ITSM.
The problem team begins by correlating the timestamps of the incident reports with historical system monitoring data for the application, network, and supporting infrastructure. They quickly identify a strong connection: the performance degradation consistently coincides with an automated, high-priority data backup process that runs every afternoon.
Digging deeper, they discover that the backup job was misconfigured; it was running with an excessively high network priority, consuming a significant amount of bandwidth and CPU resources, effectively throttling the application for any user on that network segment.
The problem team then collaborates with the infrastructure operations group to reschedule the backup to run during off-peak hours (overnight) and lowers its network priority. The permanent fix is implemented, the "slow performance" incidents cease entirely, and a widespread, frustrating user experience is eliminated before it could escalate into a major business-critical issue.
Common Questions About Incident and Problem Management
Even with a strong theoretical understanding, the practical lines between incident and problem management can become blurred in real-world IT operations. Let's address some of the most frequently asked questions that arise when teams strive to optimize these critical processes.
Can an Incident Become a Problem?
Absolutely, and this is a common pathway for problems to be discovered. An incident is a prime candidate for a problem investigation when it meets certain criteria: it's either a major, show-stopping event with no immediately apparent cause, or it's a recurring "minor" incident that keeps cropping up repeatedly.
Think of it as a crucial baton pass: the incident management team's immediate focus is on restoring service. Once the immediate crisis is contained and service is resumed, they hand over the "why did this happen?" question to problem management. The problem team then investigates the root cause, aiming to implement preventative measures.
A single, isolated server crash? That's an incident. The same server crashing every Friday afternoon, or the same application exhibiting memory leaks after every major release? That clearly indicates a systemic problem requiring a thorough investigation and a permanent solution.
Do Small Businesses Need Separate Teams?
Not always separate teams, but you unequivocally need separate processes and mindsets. In smaller organizations, it's common for an IT professional to wear multiple hats, potentially serving as both the Incident Manager and the Problem Manager. The key is to consciously switch between these roles, understanding the distinct objectives and approaches of each.
The real challenge for smaller teams isn't about having different personnel, but about allocating dedicated, protected time for problem management activities. Without this deliberate allocation, it's incredibly easy to get trapped in an endless cycle of firefighting, perpetually reacting to symptoms without ever addressing the root causes that create the fires.
Discipline is paramount. IT professionals must consciously shift from the reactive, "fix-it-now" mindset of incident response to the proactive, analytical, and patient mindset required for a comprehensive problem investigation. Even blocking out a few hours each week to systematically review recurring incidents and initiate problem records can yield significant long-term benefits in stability and efficiency.
What Is a Known Error and How Does It Help?
A known error is a specific problem for which the root cause has been identified and a temporary workaround has been developed, but a permanent fix has not yet been implemented. This concept is one of the most powerful and synergistic links between problem and incident management.
The problem management team is responsible for documenting these known errors in a centralized database, often called a Known Error Database (KEDB). This KEDB becomes an invaluable resource for the incident management team and the service desk.
When a new incident arises that matches an existing known error, service desk analysts or incident responders don't need to embark on a fresh troubleshooting journey. They can quickly consult the KEDB, retrieve the documented root cause and the proven workaround, and apply it immediately. This dramatically reduces Mean Time To Resolve (MTTR), minimizes service disruption, and significantly enhances user satisfaction while the permanent solution is being developed and deployed through the change management process. The KEDB is a cornerstone of knowledge management within ITIL.
Ready to master the concepts that power effective IT service management and excel in your certifications? At MindMesh Academy, we provide expert-curated study materials and evidence-based learning methods for certifications like ITIL, CompTIA, AWS, and PMP. Accelerate your career and build the skills to tackle real-world challenges by visiting ITIL 4 Foundation Practice Exams.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 15 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.