Your AWS Data Engineer Roadmap For 2026
Your AWS Data Engineer Roadmap For 2026
In the rapidly evolving landscape of cloud computing, the role of an AWS Data Engineer has become paramount. Far beyond simple data management, these professionals are the architects and engineers behind the complex data ecosystems on Amazon Web Services. They design, build, and maintain the robust pipelines and infrastructure that transform raw, often chaotic, information into structured, actionable insights crucial for business intelligence, machine learning, and generative AI initiatives. This demanding yet highly rewarding career blends core software engineering principles with specialized expertise in databases, data warehousing, and cutting-edge cloud architecture. At MindMesh Academy, we understand the critical skills needed for this role and have crafted this comprehensive roadmap to guide aspiring and current IT professionals.
The AWS Data Engineer Landscape in 2026
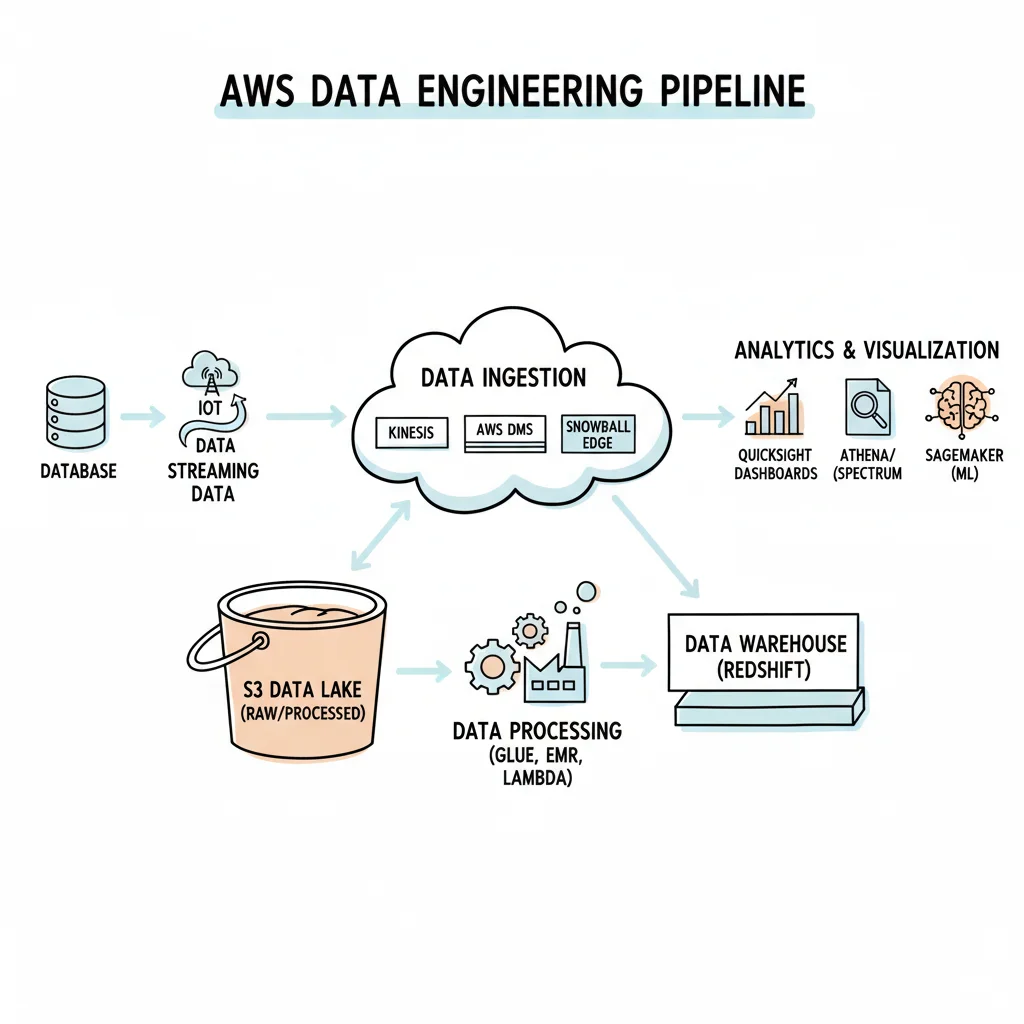
The scope of an AWS Data Engineer's role has expanded dramatically, moving beyond traditional ETL (Extract, Transform, Load) processes to encompass the architecture of an organization's entire data backbone. This foundational layer supports critical functions, from real-time operational analytics to the sophisticated data pipelines fueling advanced generative AI models. As organizations grapple with an unprecedented volume and velocity of data, the demand for professionals adept at building scalable, resilient, and cost-effective data systems on AWS has skyrocketed. This isn't merely a trend; it's a paradigm shift in how modern enterprises leverage data for competitive advantage.
The growth trajectory for this specialization is remarkable. Projections for 2026 indicate a 49% increase in the data engineer role over the preceding four years, significantly outpacing other data-centric professions such as data analysts (12.6%) and data scientists (11.7%). This highlights an urgent market need for these specialized skills. For a deeper dive into these market dynamics, consider watching this insightful analysis of the current data job market.
Core Responsibilities and Impact
Fundamentally, an AWS Data Engineer is the lynchpin ensuring that an organization's data is not only available and reliable but also transformed into an immediately usable asset for downstream consumers like data analysts and scientists. They act as the primary enablers of data-driven decision-making. Their daily responsibilities span several critical domains:
- Designing Data Pipelines: This involves creating automated, efficient workflows to ingest data from diverse sources—be it transactional databases, application logs, or IoT device streams—and consolidate it into a central repository, often an Amazon S3 data lake. In certification exams, you might face scenarios requiring you to choose the most appropriate ingestion service for different data velocities and volumes.
- Managing Data Infrastructure: Professionals in this role are responsible for provisioning, configuring, and optimizing key data services. This includes setting up and fine-tuning data warehouses like Amazon Redshift for analytical queries or implementing AWS Glue for serverless data integration and ETL processes. Understanding the operational aspects and cost implications of these services is crucial.
- Ensuring Data Quality: Raw data is almost universally imperfect. A significant part of the role is to engineer robust data validation, cleansing, and standardization mechanisms within pipelines to guarantee data accuracy and trustworthiness. This minimizes 'garbage in, garbage out' scenarios.
- Optimizing for Performance and Cost: Operating in the cloud means being acutely aware of resource consumption. A proficient data engineer continuously seeks ways to enhance pipeline efficiency, reduce processing times, and minimize compute and storage costs, making them an indispensable asset to any organization.
The true value of a data engineer lies in their unique ability to bridge the chasm between raw, often chaotic data and the clean, structured information that directly fuels strategic business decisions. They are the architects of the data superhighways upon which data scientists and analysts navigate.
To better understand where the Data Engineer fits, it helps to see how the role compares to its data-focused peers.
Reflection Prompt: Consider a recent data challenge in your own experience or industry. How might an AWS Data Engineer's skills have been applied to transform that raw data into actionable insights?
Data Roles at a Glance: Data Engineer vs. Analyst vs. Scientist
| Aspect | AWS Data Engineer | Data Analyst | Data Scientist |
|---|---|---|---|
| Primary Goal | Design, build, and maintain scalable data infrastructure and robust data pipelines. | Explore and analyze structured data to uncover actionable business insights and trends. | Develop and deploy predictive models, machine learning algorithms, and advanced analytical solutions. |
| Core Skills | Python, SQL (advanced), AWS services (S3, Glue, Redshift, Kinesis), data modeling, ETL/ELT principles, distributed computing. | SQL, data visualization (Tableau, Power BI), statistical analysis, business domain knowledge, effective communication. | Python/R (advanced), machine learning (supervised/unsupervised), deep learning, statistical modeling, advanced mathematics, algorithm design. |
| Main Tools | AWS Glue, Spark, Kinesis, Redshift, Lambda, Airflow, Step Functions, EMR. | Excel, SQL, Tableau, Power BI, Google Analytics, reporting tools. | Jupyter Notebooks, Scikit-learn, TensorFlow, PyTorch, Spark MLlib, SageMaker. |
| Typical Output | Reliable data pipelines, optimized data lakes, data warehouses, and data marts. | Dashboards, reports, ad-hoc analyses, business recommendations, performance metrics. | Machine learning models, predictive forecasts, A/B test designs, research findings, data products. |
| Salary Range (US) | $120,000 - $180,000+ | $70,000 - $110,000 | $130,000 - $200,000+ |
This detailed comparison clearly illustrates the foundational nature of the Data Engineer's work. Without their meticulous efforts in building and maintaining reliable data infrastructure, data analysts and scientists would lack the clean, trustworthy, and readily available data essential for their respective functions.
Why Is This Role So Critical Now?
The escalating demand for AWS Data Engineers stems from the unprecedented scale, diversity, and complexity of modern data. Organizations are no longer content with analyzing historical transactional data; they seek to derive immediate insights from continuous streams of sensor data from IoT devices, dynamic clickstreams from user interactions, and vast quantities of unstructured text from social media and customer feedback.
An AWS data engineer possesses the unique expertise to harness this data deluge on the world's leading cloud platform. They skillfully integrate and orchestrate a suite of services, such as Amazon Kinesis for processing live data streams, AWS Lambda for event-driven, serverless data transformations, and AWS Step Functions for building resilient, complex data workflows. This mastery over the AWS ecosystem is precisely what enables companies to unlock critical insights, fostering a significant competitive advantage in 2026 and well into the future. For those new to the AWS ecosystem, a solid starting point is exploring foundational services. MindMesh Academy offers a high-level introduction to core AWS services that can quickly familiarize you with essential concepts.
Laying the Groundwork: Your Core Skillset
Before diving into the intricacies of the AWS console, it's imperative to establish a robust foundation in core data engineering principles. The most effective data engineers are not merely adept at navigating AWS services; they are masters of data fundamentals. While AWS provides a formidable toolkit, these services remain inert without a profound understanding of foundational programming, database interaction, and data structure design. The true differentiator lies in comprehending why a particular service is selected and how it addresses a complex, real-world business challenge. This section outlines the absolutely non-negotiable skills that form the bedrock of an AWS Data Engineer's expertise.
Get Good at Python—Really Good
Python stands as the undisputed lingua franca of data engineering, and for excellent reasons. However, mere syntactic familiarity is insufficient. True proficiency mandates fluency in the powerful libraries that perform the heavy lifting within data pipelines. For an aspiring AWS Data Engineer, two libraries are absolutely indispensable:
- Pandas: This acts as your versatile toolkit for efficient data manipulation and analysis. You must be comfortable with DataFrames, capable of cleaning raw datasets, intelligently handling missing values, and performing complex joins across disparate data sources. For instance, you might leverage Pandas within an AWS Lambda function to rapidly parse and reshape incoming JSON or CSV files before persisting them to an S3 bucket or a database.
- Boto3: This is the official AWS SDK for Python, serving as your programmatic interface to the entire AWS ecosystem. Mastering Boto3 empowers your code to interact seamlessly with virtually any AWS service. You'll utilize it to programmatically upload files to Amazon S3, trigger an AWS Glue job, or dynamically provision cloud resources. A deep understanding of Boto3 is what elevates an engineer from simply navigating the console to building truly automated, infrastructure-as-code solutions.
Practical Exercise: As a valuable project for your portfolio, try writing a Python script that fetches data from a public API (e.g., a weather API), cleans and transforms it using Pandas, and then employs Boto3 to upload the processed data (perhaps in CSV or Parquet format) to a versioned S3 bucket. This exercise covers several core skills.
Reflection Prompt: Think about a repetitive manual task you've encountered in data management. How could a Python script, utilizing Pandas and Boto3, automate and optimize that process?
Move Way Beyond Basic SQL
SQL is the fundamental language of data interaction, a skillset an AWS Data Engineer will engage with daily. Whether querying data warehouses like Amazon Redshift, performing ad-hoc analysis with Amazon Athena, or managing relational databases on Amazon RDS, your SQL proficiency must extend far beyond basic SELECT statements. To manage and transform data at scale, comfort with advanced concepts is imperative:
- Complex Joins and Set Operations: You must confidently join multiple large tables, understanding the performance characteristics and appropriate use cases for
INNER JOIN,LEFT JOIN,FULL OUTER JOIN, andCROSS JOIN. Furthermore, masteringUNION,INTERSECT, andEXCEPTfor combining or comparing result sets is critical for data integration tasks. - Window Functions: These are indispensable for analytical queries. Tasks like calculating running totals, moving averages, ranking entities within groups (e.g.,
RANK(),ROW_NUMBER()), or comparing values across rows (e.g.,LAG(),LEAD()) are common requirements that are efficiently solved with window functions. In certification exams, scenario questions often test your ability to apply these. - Performance Tuning: The ability to optimize slow queries is a game-changer. This includes knowing how to interpret an
EXPLAINorEXPLAIN ANALYZEplan, creating appropriate indexes, understanding partitioning strategies, and selecting optimal distribution keys in massively parallel processing (MPP) warehouses like Redshift. A single, well-optimized query can dramatically reduce pipeline runtimes and associated compute costs, a skill highly valued in the real world and tested in exams. - Common Table Expressions (CTEs): Mastering CTEs (using
WITHclauses) helps in breaking down complex queries into readable, modular, and reusable sub-queries, significantly improving query clarity and maintainability.
The capacity to write clean, highly performant SQL queries is a true superpower for a data engineer. It frequently dictates whether a critical data pipeline completes in minutes or hours, directly influencing the timeliness and availability of essential business intelligence.
Think Like an Architect: Data Modeling & Warehousing
Beyond coding and querying, a critical skill for an AWS Data Engineer is the ability to think like an architect, particularly concerning data structure for analytical purposes. Data modeling serves as the blueprint for your data warehouse and data lake, ensuring that data is organized logically, optimized for query performance, and easily consumable by analysts and reporting tools. Familiarity with the core concepts driving robust data architecture is non-negotiable:
- Star Schema: This is the industry-standard and most widely adopted dimensional model for data warehouses. It consists of a central fact table (containing quantitative measures like sales figures or event counts) surrounded by several dimension tables (providing descriptive context, such as customer demographics, product details, or time attributes). Understanding when and how to implement a star schema is fundamental for analytical performance.
- Snowflake Schema: A more normalized variation of the star schema, where dimension tables are further broken down into sub-dimension tables. While it can reduce data redundancy and save storage space, it typically increases query complexity due to more joins. Knowing the trade-offs between star and snowflake schemas is often a point of discussion in interviews and certification scenarios.
- ETL vs. ELT: A crucial distinction in modern data architectures.
- ETL (Extract, Transform, Load): Data is extracted from source systems, transformed outside the data warehouse (often using dedicated processing engines), and then loaded into the target. This was common with traditional on-premise warehouses.
- ELT (Extract, Load, Transform): Data is extracted, immediately loaded raw into a powerful cloud data lake (like S3) or data warehouse (like Redshift), and then transformed within the warehouse using its immense processing power. In the cloud era, the ELT approach is often preferred for its flexibility, scalability, and ability to retain raw data for future use. Certification questions frequently test your understanding of which approach is best suited for various cloud data scenarios.
These aren't merely theoretical constructs; they are the architectural principles underpinning your design decisions. Knowing when a star schema is the optimal choice for a reporting requirement or why an ELT pattern is superior for handling diverse, high-volume data streams on AWS is what defines an effective and strategic AWS Data Engineer.
Mastering the Core AWS Data Services
With a solid grasp of Python, SQL, and data modeling, you're now poised to architect and implement robust, real-world data solutions on AWS. A significant aspect of the AWS data engineer role involves understanding how to integrate a diverse suite of services, each meticulously chosen to perform a specific function within the data's lifecycle—from initial ingestion to storage, complex processing, and final orchestration. This holistic, lifecycle-driven approach is paramount for constructing data pipelines that are not only functional but also highly efficient, scalable, and resilient. The market's appetite for these specialized skills is undeniable. The global data engineering services market is projected to reach an astounding $213 billion by 2026, driven by an annual creation of a mind-boggling 230-240 zettabytes of data. This data explosion places AWS data experts at the forefront of one of the fastest-growing and most critical careers in technology. For more detailed insights into this rapid market growth, refer to usdsi.org. The following core AWS services leverage and extend your foundational Python and SQL expertise.
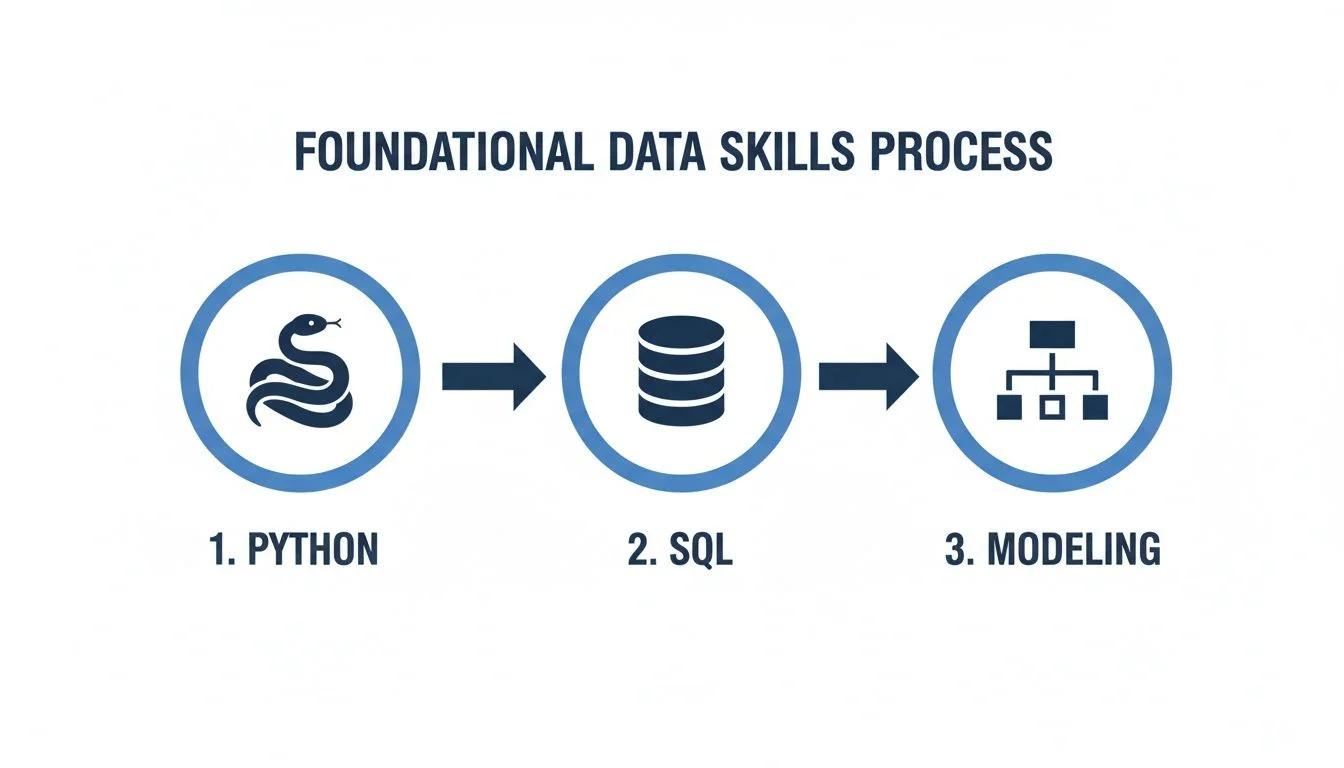 Caption: Visualizing the foundational skills: Python and SQL underpin effective data modeling, which together form the bedrock for mastering AWS data services.
Caption: Visualizing the foundational skills: Python and SQL underpin effective data modeling, which together form the bedrock for mastering AWS data services.
This visual representation underscores the logical progression: starting with coding and querying, then advancing to the architectural mindset that dictates the assembly of entire data systems.
Capturing Data with Ingestion Services
The initial phase of any data pipeline involves securely and efficiently bringing data into your AWS environment. The selection of the appropriate ingestion service is critically dependent on the data's characteristics—its velocity, volume, and source. Understanding these distinctions is often tested in certification exams.
- For Real-Time Streaming Data: For high-throughput, continuous streams of information, such as website clickstreams, social media feeds, or sensor data from IoT devices, AWS Kinesis is the industry standard. Kinesis offers several services:
- Kinesis Data Streams: Built to capture and store gigabytes per second of data, enabling real-time processing with low latency. Imagine an e-commerce platform powering a live dashboard of trending products; Data Streams can capture every click and add-to-cart event instantly.
- Kinesis Data Firehose: A fully managed service for delivering real-time streaming data to destinations like Amazon S3, Amazon Redshift, or Amazon OpenSearch Service. It can also perform basic transformations and conversions before delivery.
- For Database Migration and Replication: When dealing with one-time migrations or continuous data replication from existing databases (e.g., migrating an on-premises MySQL database to Amazon RDS or Amazon Aurora), AWS Database Migration Service (DMS) is the ideal choice. DMS simplifies the process of syncing data between heterogeneous or homogeneous database types, minimizing downtime and ensuring data integrity throughout the migration. It supports various sources and targets, making it a flexible tool for modernization initiatives.
Storing Data for Scale and Accessibility
Once successfully ingested, data requires a strategic storage solution that dictates its accessibility, processability, and governance throughout its lifecycle. The paramount decision here is often between, or more commonly, a combination of, a data lake and a data warehouse. This choice is a frequent topic in AWS certification design scenarios.
- Amazon S3 (Simple Storage Service) - The Data Lake Foundation: The modern data lake is almost universally constructed upon Amazon S3. As an object storage service, S3 offers unmatched durability, availability, and virtually infinite scalability. It serves as the perfect landing zone for vast quantities of raw, unstructured, and semi-structured data—such as images, video, log files, sensor data, and JSON blobs—retained in its original format. This "store first, schema later" flexibility makes S3 the cornerstone of nearly every contemporary AWS data architecture, enabling diverse analytical workloads without upfront schema constraints.
- Amazon Redshift - The Petabyte-Scale Data Warehouse: For clean, highly structured data requiring rapid query performance for sophisticated analytical workloads, Amazon Redshift is the go-to solution. It is a fully managed, petabyte-scale cloud data warehouse. Redshift employs columnar storage and massively parallel processing (MPP) to deliver lightning-fast query results on large datasets, making it ideal for powering business intelligence dashboards, ad-hoc analyses, and complex SQL-driven reporting.
The critical architectural consideration is rarely "S3 versus Redshift?" but rather "S3 and Redshift." A robust, modern data platform leverages an S3 data lake for cost-effective, flexible storage of raw and diverse data, complemented by a Redshift data warehouse for curated, high-performance analytical datasets. Understanding this symbiotic relationship is key to designing effective data solutions and excelling in AWS certification exams.
Transforming Data with Processing Engines
Raw data, in its initial state, seldom offers immediate business value. The processing stage is where expertise in transformation engines truly shines—it's here that data is cleaned, filtered, enriched, and reshaped from disparate raw material into a refined, valuable asset. Choosing the right processing tool is a common scenario in certification exams.
- AWS Glue - Serverless ETL and Data Catalog: For fully managed, serverless ETL (Extract, Transform, Load) operations, AWS Glue is a transformative service. It offers a powerful set of capabilities:
- Glue Crawlers: Automatically discover schemas and partitions from data stored in Amazon S3 or databases, populating the central Glue Data Catalog. This metadata repository makes data discoverable and queryable by other AWS services like Athena and Redshift Spectrum.
- Glue ETL Jobs: Run Python or Apache Spark jobs to transform data without requiring you to provision or manage any servers. It automatically scales resources as needed, making it ideal for event-driven or scheduled batch processing.
- Glue DataBrew: A visual data preparation tool for analysts and data scientists to clean and normalize data with a drag-and-drop interface. Understanding Glue's capabilities and its integration with other services is critical for the AWS Certified Data Engineer - Associate exam. For a detailed comparison of batch ETL tools, you can consult our guide on AWS Glue, EMR, and Athena.
- Amazon EMR (Elastic MapReduce) - Big Data Processing: When you require more granular control over your computing environment, specific versions of big data frameworks, or have truly massive, complex big data workloads, Amazon EMR is your choice. EMR allows you to easily provision and manage scalable clusters of EC2 instances to run popular open-source frameworks like Apache Spark, Hadoop, Presto, and Hive. A classic use case involves processing terabytes of application logs to uncover intricate user behavior patterns, perform large-scale machine learning, or run complex graph analytics. EMR offers flexibility for custom configurations and performance tuning that might be needed for highly specialized applications.
Orchestration and Querying Your Data
The culmination of data pipeline construction involves orchestrating these disparate services into coherent, automated workflows and providing efficient means for end-users to query and consume the processed data. These services are vital for building complete, production-ready data solutions and are frequently featured in certification practical scenarios.
- AWS Step Functions - Workflow Orchestration: This is your enterprise-grade workflow coordinator, enabling you to build complex, multi-step data pipelines as visual state machines. Step Functions offer robust features like built-in error handling, automatic retries, and parallel execution, ensuring pipeline resilience and reliability. For example, you could design a workflow that initiates an AWS Glue ETL job, awaits its successful completion, and then automatically triggers a refresh of a corresponding table in Amazon Redshift or publishes a notification to Amazon SNS upon success or failure.
- Amazon Athena - Serverless Querying for Data Lakes: Amazon Athena is a powerful, serverless interactive query service that empowers users to analyze data directly in Amazon S3 using standard SQL. This is a significant time-saver and a cornerstone of data lake analytics. With Athena, data analysts and engineers can immediately explore raw, semi-structured, or structured data residing in an S3 data lake, without the need to load it into a database first. It dramatically accelerates ad-hoc analysis, data discovery, and prototyping for new analytical insights, integrating seamlessly with the AWS Glue Data Catalog.
Your Strategic AWS Certification Path
AWS Certifications transcend mere resume embellishments; they serve as a meticulously structured roadmap, validating your expertise to potential employers. For an ambitious AWS data engineer, a well-thought-out certification strategy demonstrates mastery of the specific services, architectural patterns, and best practices essential for the role. It’s a testament to practical competence, not just rote memorization. Your professional journey must logically commence with a robust, foundational understanding of cloud computing. While the allure of specialized data exams is strong, a lack of core cloud fluency will inevitably lead to foundational gaps. Seasoned professionals consistently advise building a comprehensive understanding of AWS fundamentals before delving into the intricacies of data pipeline construction.
The Foundational Starting Point
For the majority of aspiring cloud professionals, the optimal first step is the AWS Certified Cloud Practitioner certification. This credential is akin to acquiring the foundational lexicon of AWS. While it doesn't delve into the specifics of building intricate data pipelines, it meticulously covers essential concepts: the shared responsibility model, core AWS services (compute, storage, networking), fundamental security principles, and—critically—AWS pricing and billing. Without this baseline understanding, navigating the broader AWS ecosystem and comprehending how data services seamlessly integrate becomes a significant challenge. Successfully passing this exam instills the confidence and provides the necessary vocabulary to effectively engage with more advanced, role-specific certifications.
The Core Certification for Data Engineers
Following the establishment of your foundational cloud knowledge, your primary objective should be the AWS Certified Data Engineer - Associate certification. This credential is meticulously designed to validate the precise skills and knowledge demanded by this specialized role, encompassing the entire data lifecycle on AWS. The exam's domain breakdown directly reflects the day-to-day responsibilities and technical expertise required of a data engineer. Here’s a detailed alignment of the exam domains with the services and concepts you must master:
- Data Ingestion and Transformation (34%): This domain focuses on techniques and services for efficiently bringing data into your AWS environment and preparing it for analysis. Expect questions on AWS Glue for ETL operations, AWS Database Migration Service (DMS) for database migrations, and Amazon Kinesis for real-time streaming data ingestion. You'll need to demonstrate knowledge of choosing the right tool for different data types and velocities.
- Data Store Management (26%): This section evaluates your understanding of various AWS data storage solutions. Key services include Amazon S3 for data lakes (raw, unstructured data), Amazon Redshift for data warehouses (structured, analytical data), and Amazon DynamoDB for NoSQL use cases (high-performance, non-relational data). The focus is on selecting appropriate storage based on data characteristics, access patterns, and cost.
- Data Operations and Governance (20%): This domain assesses your ability to build, monitor, and secure operational data pipelines. It covers orchestrating complex workflows with AWS Step Functions, managing data access and permissions with AWS Lake Formation, and monitoring pipeline health with Amazon CloudWatch. Understanding data lineage, auditing, and recovery strategies is also crucial.
- Data Security and Monitoring (20%): This final domain emphasizes securing data at rest and in transit, and continuously monitoring pipeline performance and issues. You'll be tested on implementing encryption, managing granular access control with AWS Identity and Access Management (IAM), and utilizing CloudWatch for logging and alarming.
This certification is not merely a test of recall; it rigorously assesses your ability to apply knowledge. Exam questions are predominantly scenario-based, challenging you to identify the most efficient, cost-effective, secure, or scalable solution for realistic data engineering problems on AWS.
Key Takeaway: The AWS Certified Data Engineer - Associate exam is designed to mirror real-world challenges. Focus on understanding why certain services are chosen for specific scenarios, not just what they do.
Broadening Your Architectural Perspective
While the Data Engineer - Associate is your direct professional credential, pursuing the AWS Certified Solutions Architect - Associate can profoundly enhance your career trajectory. This certification compels you to adopt an architectural perspective, focusing on designing highly available, fault-tolerant, scalable, and cost-optimized systems across the entire AWS platform. For an AWS data engineer, cultivating this broader architectural mindset is invaluable. It equips you to build data pipelines that are not only functional for current demands but also resilient and scalable enough to accommodate future business growth and evolving data requirements. You learn to visualize the entire ecosystem, understanding how your data solutions integrate with compute, networking, and security services, rather than solely focusing on the data domain. You can discover a wealth of official and community study resources for all these critical AWS certifications, including those offered by MindMesh Academy, to support your preparation.
AWS Certifications for Data Engineers: Your Learning Pathway
Here's a breakdown to help you decide which certification makes sense for you right now, and what you should be aiming for next.
| Certification | Focus Area | Ideal For | Key AWS Services Covered |
|---|---|---|---|
| Cloud Practitioner | Foundational cloud concepts, global infrastructure, security, billing, and core services overview. | Professionals new to AWS or those in non-technical roles needing cloud literacy. | IAM, S3, EC2, VPC, RDS, Lambda, DynamoDB, CloudWatch, Billing & Cost Management |
| Data Engineer - Associate | End-to-end data pipeline design, implementation, management, and optimization on AWS. | Aspiring or current data engineers specializing in AWS data services and architectures. | Glue, Kinesis, Redshift, S3, DMS, Step Functions, Athena, EMR, Lake Formation |
| Solutions Architect - Associate | General system design, building scalable, highly available, resilient, and cost-effective architectures. | Engineers seeking a broader understanding of AWS architectural best practices across diverse workloads. | EC2, VPC, S3, IAM, Route 53, Lambda, ELB, Auto Scaling, RDS, CloudFront, Security Group concepts |
Ultimately, consider your certification path as a strategic career accelerator. Begin with a solid cloud foundation, achieve mastery in core data engineering skills, and then broaden your perspective with architectural insights. This methodical approach doesn't just prepare you for exams; it cultivates the practical, battle-tested expertise highly sought after by leading organizations.
Building Projects That Get You Hired
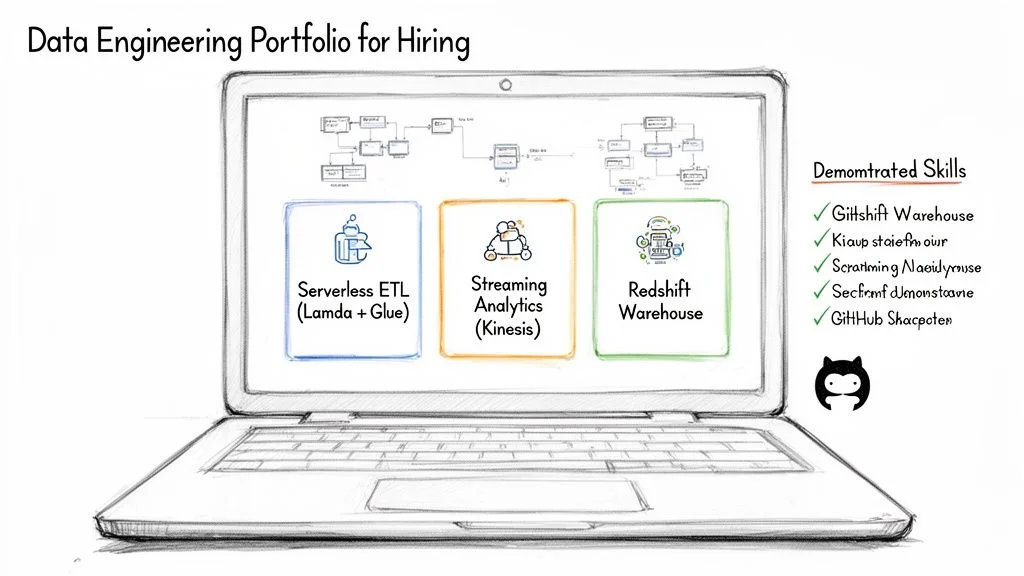 Caption: A compelling data engineering portfolio showcases practical skills through projects like serverless ETL pipelines, real-time streaming analytics, and robust data warehouse solutions.
Caption: A compelling data engineering portfolio showcases practical skills through projects like serverless ETL pipelines, real-time streaming analytics, and robust data warehouse solutions.
While certifications are invaluable for passing initial resume screenings, it is a robust portfolio of hands-on projects that truly secures a job offer. This is your opportunity to transcend theoretical knowledge and demonstrate tangible proof of your ability to design, build, and troubleshoot real-world data solutions. The objective isn't merely to replicate tutorials, but to construct end-to-end systems that you can confidently present and articulate in an interview. Be prepared to elaborate on your architectural choices, discuss the challenges encountered, and explain your problem-solving methodologies.
Project Idea 1: Serverless ETL Pipeline
A serverless ETL pipeline is an exemplary project, showcasing proficiency in building highly scalable and cost-effective data solutions without the operational overhead of server management—a highly coveted skill for any AWS Data Engineer. This type of project effectively demonstrates your understanding of cloud-native architectures.
Scenario: You need to ingest user clickstream data from a web application, perform necessary cleaning and transformation, and then land it into a data lake for subsequent analytical querying.
Proposed Architecture:
- Ingestion (API Gateway & Lambda): Begin with an Amazon API Gateway provisioned with a REST endpoint. This gateway will receive the raw JSON clickstream data from the web application. The API Gateway then triggers an AWS Lambda function, initiating the serverless processing workflow.
- Processing (Lambda & Pandas): The triggered Lambda function, authored in Python, forms the core of your transformation logic. Here, you'll leverage libraries like Pandas to validate, clean, normalize, and reshape the messy JSON data into a structured format. This demonstrates your Python data manipulation skills.
- Storage (S3 & Parquet/Partitioning): Once processed, the clean, structured data is persisted to an Amazon S3 bucket. A best practice here is to store the data in an optimized columnar format like Parquet and partition it by date (e.g.,
s3://your-bucket/clickstream/year=YYYY/month=MM/day=DD/). This significantly enhances query performance and reduces costs when analysts use services like Athena. - Cataloging (AWS Glue Crawler): Finally, configure an AWS Glue Crawler to run on a scheduled basis. The crawler will automatically scan your S3 bucket, infer the schema of your processed Parquet files, and update the AWS Glue Data Catalog. This makes your data lake assets discoverable and immediately queryable by services like Amazon Athena or Amazon Redshift Spectrum.
This single, end-to-end project vividly demonstrates your command of serverless computing, data processing fundamentals, and best practices for data lake architecture.
A meticulously documented project on GitHub transcends mere code; it crafts a compelling narrative of your problem-solving capabilities. Your
README.mdshould lucidly explain the 'why' behind your architectural decisions, not just merely detail the 'how.'
Project Idea 2: Real-Time Streaming Analytics
After demonstrating proficiency with batch data processing, the next step is to showcase your ability to handle data in motion. A real-time streaming analytics project proves you can deliver immediate insights as events unfold—a critical skill for use cases spanning fraud detection, operational monitoring, and social media sentiment analysis.
Scenario: Design a pipeline to analyze a live stream of social media mentions, performing real-time sentiment analysis to identify immediate trends or issues.
Proposed Architecture:
- Stream Ingestion (Kinesis Data Stream): A lightweight Python script or mock data generator acts as your data producer, pushing simulated social media posts (e.g., JSON objects containing text and metadata) into an Amazon Kinesis Data Stream. This establishes a high-throughput, real-time data ingestion layer.
- Transformation and Delivery (Kinesis Data Firehose & Lambda): Next, Amazon Kinesis Data Firehose subscribes to this Data Stream. Firehose is configured to automatically batch the incoming records and invoke an AWS Lambda function you provide. This Lambda function performs real-time sentiment analysis on each social media post (e.g., using a simple NLP library or even a pre-trained ML model).
- Analytics & Storage (S3 & OpenSearch): From Firehose, the enriched data (including sentiment scores) can be delivered to two distinct destinations simultaneously: an Amazon S3 bucket for cost-effective, long-term archival and future batch processing, and an Amazon OpenSearch Service cluster (formerly Amazon Elasticsearch Service) to power a live, interactive dashboard for real-time visualization of sentiment trends.
This architecture demonstrates your ability to construct low-latency pipelines that provide immediate, actionable value. To further diversify your portfolio and gain more practical experience, explore a variety of other hands-on, inscriptive projects.
Documenting Your Work for Maximum Impact
Having meticulously engineered a compelling project, the final, yet equally crucial, step is its professional presentation. A mere repository of code on GitHub is insufficient; you must craft a narrative. For each project, develop a comprehensive README.md file that serves as its executive summary and technical documentation. This file should include:
- A concise yet clear project overview, articulating the business problem it addresses and the value it delivers.
- A high-level architecture diagram (e.g., using ASCII art, Mermaid, or a simple image) visually depicting all utilized AWS services and the logical data flow between them.
- Detailed, step-by-step instructions on how another individual could set up, configure, and execute your project, including any prerequisites.
- Key code snippets accompanied by clear explanations of their function and significance, highlighting any clever optimizations or design patterns used.
- A section on "Challenges and Learnings," discussing obstacles encountered and how you overcame them, demonstrating problem-solving skills.
This level of thorough documentation transforms your code from a mere script into a compelling case study of your capabilities, presenting you as not just a proficient coder but a capable and thoughtful AWS Data Engineer.
Getting Ready for Your Data Engineer Interview
Having diligently built your technical skills and curated a robust project portfolio, the ultimate challenge awaits: the interview. This critical stage assesses not only your knowledge but, more importantly, your analytical and problem-solving abilities. Expect a blend of rigorous technical deep dives and insightful behavioral questions designed to evaluate your fit within a team environment. The technical assessment will invariably focus on your proficiency in Python, SQL, and AWS architecture. Be prepared for live coding exercises, whiteboard system design challenges, or in-depth discussions. Interviewers are less concerned with a perfectly optimized solution on the first try and more interested in your methodical problem-solving approach, code clarity, and articulate explanation of your thought process.
Tackling the Technical Questions
The primary objective of the technical interview round is to ascertain your ability to translate theoretical knowledge into practical solutions for real-world business challenges. It is a comprehensive assessment of practical application.
- Python: Expect tasks such as writing a script to parse and cleanse complex JSON or CSV data, or articulating how you would leverage the Boto3 library to programmatically automate specific AWS infrastructure or data processing tasks (e.g., uploading files to S3, triggering Glue jobs).
- SQL: Be prepared to construct sophisticated queries involving multiple joins, advanced window functions, subqueries, and common table expressions. A frequently encountered scenario involves optimizing a given slow-performing query, requiring you to explain your thought process for identifying bottlenecks (e.g., missing indexes, inefficient joins) and proposing solutions.
- AWS Architecture (System Design): This is where your architectural prowess is tested. A typical question might be: "Design a scalable, highly available, and cost-effective pipeline to process real-time clickstream data for an operational dashboard, ensuring data quality and security." Here, you'll need to demonstrate knowledge of services like Kinesis, Lambda, S3, Glue, Redshift, and Athena, explaining how they integrate.
Crucially, during technical discussions, think out loud. Articulate your rationale, discuss potential trade-offs (e.g., cost vs. performance, complexity vs. simplicity), and justify your service selections (e.g., choosing Amazon Kinesis for low-latency streaming over Amazon SQS for message queuing, or a serverless Lambda function over a dedicated EC2 instance for event-driven tasks).
Your capacity to eloquently explain the 'why' behind your technical decisions often holds more weight than merely presenting a perfectly optimized line of code. It signifies a candidate who thinks strategically like an architect, rather than just acting as a coder.
Nailing the Behavioral Questions
The significance of behavioral questions should never be underestimated. Organizations prioritize hiring engineers who demonstrate strong teamwork, resilience in troubleshooting, and a commitment to continuous learning from failures. Many interviewers utilize the widely recognized STAR method (Situation, Task, Action, Result) to structure these inquiries. Prepare several compelling narratives derived from your project experience or previous roles. Common behavioral questions include:
- "Describe a time when a critical data pipeline unexpectedly failed in production. What steps did you take to diagnose, mitigate, and prevent recurrence?"
- "Walk me through the most technically challenging data project you’ve undertaken. What was your specific contribution, what obstacles did you face, and what was the ultimate outcome?"
- "Tell me about a time you had to collaborate with a non-technical stakeholder to understand data requirements. How did you ensure successful communication and delivery?"
By structuring your responses using the STAR method, you provide clear, concise, and impactful stories that effectively highlight your accomplishments and transferable skills. The diligent preparation for these interviews yields substantial rewards. As an AWS data engineer, you are entering a field characterized by immense demand and competitive compensation. Median salaries typically hover around $131,000 annually, with experienced senior roles commanding $171,000 or more. Top-tier specialists with advanced skills and experience can achieve even higher figures, often complemented by the flexibility of remote work opportunities. For further exploration of these exciting career trends and salary insights, refer to refontelearning.com.
Answering Your Top Questions About Being an AWS Data Engineer
Embarking on a specialized career path as an AWS Data Engineer naturally leads to numerous inquiries, particularly regarding the practical, day-to-day realities of the role. Let's address the most frequently asked questions to provide clarity and practical insights.
How Much Coding Do I Really Need to Know?
You absolutely need a significant amount of coding proficiency, though perhaps not in the traditional sense of a full-stack software engineer. A robust command of both Python and SQL is non-negotiable—they are your primary operational tools.
- Python: This language serves as the primary engine for automation, data transformation, and integration tasks. You'll continuously leverage Python for scripting ETL jobs with PySpark within AWS Glue or Amazon EMR, automating cloud infrastructure interactions via Boto3, and developing event-driven, serverless data functions with AWS Lambda. Focus on data manipulation libraries (Pandas), API interactions, and AWS SDK usage.
- SQL: This is the universal language of data. You will spend considerable time crafting complex queries, performing data transformations, and optimizing performance within services like Amazon Redshift, Amazon Athena, and Amazon RDS. Your SQL skills need to extend to window functions, CTEs, and performance tuning.
While the day-to-day work may not typically involve competitive programming challenges like LeetCode, the ability to write clean, efficient, well-documented, and maintainable code is paramount for constructing resilient and scalable data pipelines.
Can I Really Become an AWS Data Engineer With No Experience?
Breaking into the field of AWS Data Engineering without prior professional experience is undoubtedly challenging but entirely achievable with a strategic approach and dedicated effort. The key lies in proactively building a robust foundational skillset before actively seeking full-time roles. Focus on mastering the core technical essentials: Python, SQL, and the fundamental concepts of cloud computing on AWS.
Your most compelling asset for gaining entry will be a meticulously curated portfolio of personal projects. These projects must demonstrably prove your ability to apply theoretical knowledge to solve practical data challenges. Additionally, relevant certifications, particularly the AWS Certified Data Engineer - Associate, are invaluable for validating your knowledge and ensuring your resume successfully navigates initial screening filters. Many successful data engineers initiate their careers in adjacent roles—such as a Data Analyst, Business Intelligence Developer, or Junior Database Administrator—to gain professional exposure and build a stepping stone into dedicated data engineering roles.
Which Is More Important: Certifications or a Project Portfolio?
This is a perennially debated question, and the most accurate answer is that certifications and project portfolios serve distinct, yet complementary, purposes; ideally, you need both. A certification, such as the AWS Certified Data Engineer - Associate, functions as your entry ticket. It objectively validates a baseline understanding of the AWS ecosystem and communicates to recruiters that you possess the requisite knowledge and speak the cloud language. It significantly helps in getting your resume through initial screenings.
A project portfolio, conversely, is what truly demonstrates your ability to perform the job. It offers tangible proof of your capacity to apply theoretical knowledge to solve real-world data problems. In a technical interview, a strong, well-articulated portfolio often carries more persuasive weight than a certification alone. The optimal strategy is to build your portfolio concurrently with your certification studies. This hands-on practice not only solidifies exam concepts but also provides invaluable real-world experience. For deeper insights into what hiring managers seek, consider reviewing common Data Engineer Interview Questions and Answers.
A certification primarily secures resume visibility. A compelling project portfolio, however, is what ultimately persuades a hiring manager of your practical competence. The most effective approach integrates both: build your portfolio actively while preparing for your certification, ensuring that hands-on application reinforces theoretical understanding.
So, What Does a Typical Day Actually Look Like?
One of the most appealing aspects of an AWS Data Engineer role is its dynamic nature, ensuring that no two days are identical. Nevertheless, a typical day often involves a strategic blend of development, proactive monitoring, collaborative problem-solving, and continuous learning.
- Morning: Monitoring and Proactive Maintenance: Your day likely begins with a thorough check of existing data pipelines. Utilizing tools like Amazon CloudWatch for logs and metrics, or AWS Step Functions console for workflow status, you'll confirm that all scheduled overnight data loads and transformations completed successfully and within expected SLAs. Addressing any alerts or anomalies immediately is paramount.
- Mid-day: Deep Work and Development: This period is typically dedicated to focused technical work. You might be immersed in writing and testing Python or PySpark code for a new data pipeline in AWS Glue or on an Amazon EMR cluster, architecting transformation logic to cleanse and enrich raw datasets, or developing new data ingestion strategies using Kinesis or DMS.
- Afternoon: Collaboration, Optimization, and Troubleshooting: The afternoon often shifts towards collaborative efforts. This could involve meetings with data scientists or business stakeholders to understand new data requirements or to clarify existing data models. You might also dive into Amazon Redshift to optimize a resource-intensive SQL query, or meticulously troubleshoot a pipeline that has recently experienced a failure, dissecting logs and applying debugging techniques. Participation in team stand-ups and code reviews is also a regular activity.
Ready to turn this roadmap into reality? At MindMesh Academy, we provide expert-curated study guides and practice exams using proven methods like Spaced Repetition to help you master AWS concepts and earn your certification. Start your journey with us today and build the skills that get you hired. Find out more at AWS Cloud Practitioner Practice Exams.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 15 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.